 MySQL 是怎样运行的
MySQL 是怎样运行的
《MySQL是怎样运行的:从根儿上理解MySQL》

# 字符编码
- 字符集指的是某个字符范围的编码规则。
- 比较规则是针对某个字符集中的字符比较大小的一种规则。
- 在 MySQL 中,一个字符集可以有若干种比较规则,其中有一个默认的比较规则,一个比较规则必须对应一个字符集。
- 查看 MySQL 中查看支持的字符集和比较规则的语句如下:
SHOW (CHARACTER SET|CHARSET) [LIKE 匹配的模式];
SHOW COLLATION [LIKE 匹配的模式];
- MySQL有四个级别的字符集和比较规
- 服务器级别 charactersetserver 表示服务器级别的字符集, collationserver 表示服务器级别的比较规则。
- 数据库级别 创建和修改数据库时可以指定字符集和比较规则:
CREATE DATABASE 数据库名
[[DEFAULT] CHARACTER SET 字符集名称]
[[DEFAULT] COLLATE 比较规则名称];
ALTER DATABASE 数据库名
[[DEFAULT] CHARACTER SET 字符集名称]
[[DEFAULT] COLLATE 比较规则名称];
charactersetdatabase 表示当前数据库的字符集, collationdatabase 表示当前默认数据库的比较规则,这两个系统变量是只读的,不能修改。如果没有指定当前默认数据库,则变量与相应的服务器级系统变量具有相同的值。
- 表级别 创建和修改表的时候指定表的字符集和比较规则:
CREATE TABLE 表名 (列的信息)
[[DEFAULT] CHARACTER SET 字符集名称]
[COLLATE 比较规则名称]];
ALTER TABLE 表名
[[DEFAULT] CHARACTER SET 字符集名称]
[COLLATE 比较规则名称];
- 列级别 创建和修改列定义的时候可以指定该列的字符集和比较规则:
CREATE TABLE 表名(
列名 字符串类型 [CHARACTER SET 字符集名称]
[COLLATE 比较规则名称], 其他列...
);
ALTER TABLE 表名 MODIFY 列名 字符串类型 [CHARACTER SET 字符集名称] [COLLATE 比较规则名称];
- 从发送请求到接收结果过程中发生的字符集转换:
- 客户端使用操作系统的字符集编码请求字符串,向服务器发送的是经过编码的一个字节串。
- 服务器将客户端发送来的字节串采用 charactersetclient 代表的字符集进行解码,将解码后的字符串再按照 charactersetconnection 代表的字符集进行编码。
- 如果 charactersetconnection 代表的字符集和具体操作的列使用的字符集一致,则直接进行相应操作,否则的话需要将请求中的字符串从 charactersetconnection 代表的字符集转换为具体操作的列使用的字符集之后再进行操作。
- 将从某个列获取到的字节串从该列使用的字符集转换为 charactersetresults 代表的字符集后发送到客户端。
- 客户端使用操作系统的字符集解析收到的结果集字节串。在这个过程中各个系统变量的含义如下:
| 系统变量 | 描述 |
|---|---|
| charactersetclient | 服务器解码请求时使用的字符集 |
| charactersetconnection | 服务器处理请求时会把请求字符串从 charactersetclient 转为charactersetconnection |
| charactersetresults | 服务器向客户端返回数据时使用的字符集 |
- 一般情况下要使用保持这三个变量的值和客户端使用的字符集相同。
- 比较规则的作用通常体现比较字符串大小的表达式以及对某个字符串列进行排序中。
# InnoDB行格式
我们平时是以记录为单位来向表中插入数据的,这些记录在磁盘上的存放方式也被称为 行格式 或者 记录格式 。设计 InnoDB 存储引擎的大叔们到现在为止设计了4种不同类型的 行格式 ,分别是 Compact 、 Redundant 、Dynamic 和 Compressed 行格式,随着时间的推移,他们可能会设计出更多的行格式,但是不管怎么变,在原理上大体都是相同的。
- 页是 MySQL 中磁盘和内存交互的基本单位,也是 MySQL 是管理存储空间的基本单位。
- 指定和修改行格式的语法如下:
CREATE TABLE 表名 (列的信息) ROWFORMAT=行格式名称
ALTER TABLE 表名 ROWFORMAT=行格式名称
- COMPPACT行格式

- Redundant行格式

- Dynamic和Compressed行格式 这两种行格式类似于 COMPACT行格式 ,只不过在处理行溢出数据时有点儿分歧,它们不会在记录的真实数据处存储字符串的前768个字节,而是把所有的字节都存储到其他页面中,只在记录的真实数据处存储其他页面的地址。 另外, Compressed 行格式会采用压缩算法对页面进行压缩。
- 一个页一般是 16KB ,当记录中的数据太多,当前页放不下的时候,会把多余的数据存储到其他页中,这种现象称为 行溢出 。
# 数据页

- InnoDB为了不同的目的而设计了不同类型的页,我们把用于存放记录的页叫做 数据页 。
- 一个数据页可以被大致划分为7个部分,分别是
| 名称 | 中文名 | 占用空间大小 | 简单描述 |
|---|---|---|---|
| File Header | 文件头部 | 38 字节 | 页的一些通用信息 |
| Page Header | 页面头部 | 56 字节 | 数据页专有的一些信息 |
| Infimum + Supremum | 最小记录和最大记录 | 26 字节 | 两个虚拟的行记录 |
| User Records | 用户记录 | 不确定 | 实际存储的行记录内容 |
| Free Space | 空闲空间 | 不确定 | 页中尚未使用的空间 |
| Page Directory | 页面目录 | 不确定 | 页中的某些记录的相对位置 |
| File Trailer | 文件尾部 | 8 字节 | 校验页是否完整 |
- File Header ,表示页的一些通用信息,占固定的38字节。
- Page Header ,表示数据页专有的一些信息,占固定的56个字节。
- Infimum + Supremum ,两个虚拟的伪记录,分别表示页中的最小和最大记录,占固定的 26 个字节。
- User Records :真实存储我们插入的记录的部分,大小不固定。
- Free Space :页中尚未使用的部分,大小不确定。
- Page Directory :页中的某些记录相对位置,也就是各个槽在页面中的地址偏移量,大小不固定,插入的记录越多,这个部分占用的空间越多。
- File Trailer :用于检验页是否完整的部分,占用固定的8个字节。
- 每个记录的头信息中都有一个 nextrecord 属性,从而使页中的所有记录串联成一个 单链表 。
- InnoDB 会为把页中的记录划分为若干个组,每个组的最后一个记录的地址偏移量作为一个 槽 ,存放在Page Directory 中,所以在一个页中根据主键查找记录是非常快的,分为两步:
- 通过二分法确定该记录所在的槽
- 通过记录的next_record属性遍历该槽所在的组中的各个记录。
- 每个数据页的 File Header 部分都有上一个和下一个页的编号,所以所有的数据页会组成一个 双链表 。
- 为保证从内存中同步到磁盘的页的完整性,在页的首部和尾部都会存储页中数据的校验和和页面最后修改时对应的 LSN 值,如果首部和尾部的校验和和 LSN 值校验不成功的话,就说明同步过程出现了问题。
# 索引

B+ 树本身就是一个目录,或者说本身就是一个索引。它有两个特点:
- 使用记录主键值的大小进行记录和页的排序,这包括三个方面的含义:
- 页内的记录是按照主键的大小顺序排成一个单向链表。
- 各个存放用户记录的页也是根据页中用户记录的主键大小顺序排成一个双向链表。
- 存放目录项记录的页分为不同的层次,在同一层次中的页也是根据页中目录项记录的主键大小顺序排成一个双向链表。
- B+ 树的叶子节点存储的是完整的用户记录。
所谓完整的用户记录,就是指这个记录中存储了所有列的值(包括隐藏列)。
我们把具有这两种特性的 B+ 树称为 聚簇索引 ,所有完整的用户记录都存放在这个 聚簇索引 的叶子节点处。这种 聚簇索引 并不需要我们在 MySQL 语句中显式的使用 INDEX 语句去创建,InnoDB 存储引擎会自动的为我们创建聚簇索引。另外有趣的一点是,在 InnoDB 存储引擎中, 聚簇索引 就是数据的存储方式(所有的用户记录都存储在了 叶子节点 ),也就是所谓的索引即数据,数据即索引。
一个B+树索引的根节点自诞生之日起,便不会再移动
- 每当为某个表创建一个 B+ 树索引(聚簇索引不是人为创建的,默认就有)的时候,都会为这个索引创建一个 根节点 页面。最开始表中没有数据的时候,每个 B+ 树索引对应的 根节点 中既没有用户记录,也没有目录项记录。
- 随后向表中插入用户记录时,先把用户记录存储到这个 根节点 中。
- 当 根节点 中的可用空间用完时继续插入记录,此时会将 根节点 中的所有记录复制到一个新分配的页,比如 页a 中,然后对这个新页进行 页分裂 的操作,得到另一个新页,比如 页b 。这时新插入的记录根据键值(也就是聚簇索引中的主键值,二级索引中对应的索引列的值)的大小就会被分配到 页a 或者 页b 中,而根节点 便升级为存储目录项记录的页。
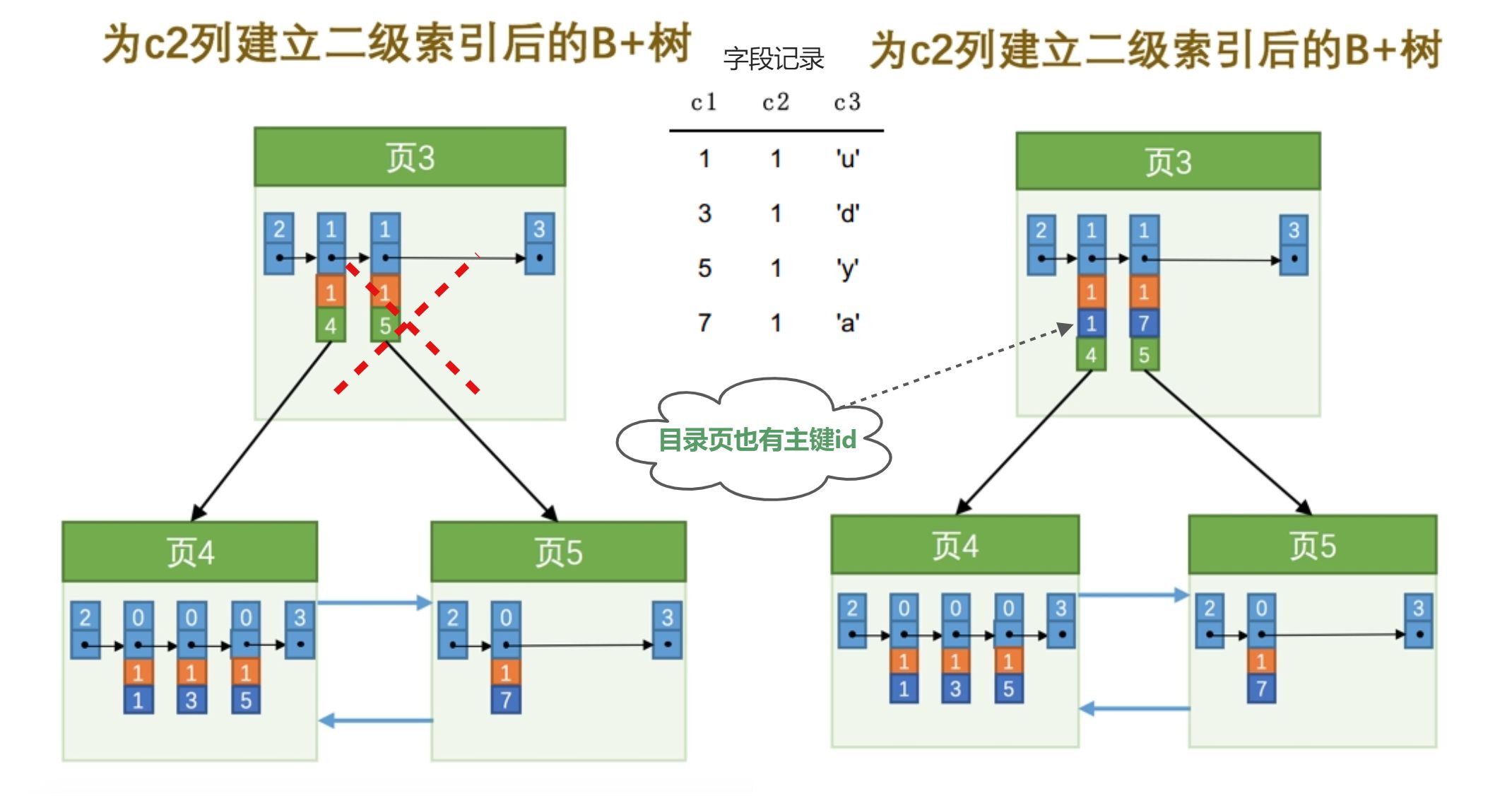
为了让新插入记录能找到自己在那个页里,我们需要保证在B+树的同一层内节点的目录项记录除 页号 这个字段以外是唯一的。所以对于二级索引的内节点的目录项记录的内容实际上是由三个部分构成的:
- 索引列的值
- 主键值
- 页号
# 一个页面最少存储2条记录
不然就相当于链表了,影响性能
# MySQL中创建和删除索引的语句
InnoDB 和 MyISAM 会自动为主键或者声明为 UNIQUE 的列去自动建立 B+ 树索引
建表时创建索引
CREATE TALBE 表名 (
各种列的信息 ··· ,
[KEY|INDEX] 索引名 (需要被索引的单个列或多个列)
)
其中的 KEY 和 INDEX 是同义词,任意选用一个就可以。我们也可以在修改表结构的时候添加索引:
ALTER TABLE 表名 ADD [INDEX|KEY] 索引名 (需要被索引的单个列或多个列)
修改表结构的时候删除索引:
ALTER TABLE 表名 DROP [INDEX|KEY] 索引名;
- B+ 树索引在空间和时间上都有代价,所以没事儿别瞎建索引。
- B+ 树索引适用于下边这些情况:
- 全值匹配
- 匹配左边的列
- 匹配范围值精确
- 匹配某一列并范围匹配另外一列
- 用于排序
- 用于分组
- 在使用索引时需要注意下边这些事项:
- 只为用于搜索、排序或分组的列创建索引
- 为列的基数大的列创建索引
- 索引列的类型尽量小
- 可以只对字符串值的前缀建立索引
- 只有索引列在比较表达式中单独出现才可以适用索引
- 为了尽可能少的让 聚簇索引 发生页面分裂和记录移位的情况,建议让主键拥有 AUTOINCREMENT 属性。
- 定位并删除表中的重复和冗余索引尽量使用 覆盖索引 进行查询,避免 回表 带来的性能损耗。
# 数据目录
物理上存放数据的地方
mysql> SHOW VARIABLES LIKE 'datadir';
# 数据库在文件系统中的表示
每个数据库都对应数据目录下的一个子目录,或者说对应一个文件夹,我们每当我们新建一个数据库时, MySQL 会帮我们做这两件事儿:
- 在 数据目录 下创建一个和数据库名同名的子目录(或者说是文件夹)。
- 在该与数据库名同名的子目录下创建一个名为
db.opt的文件,这个文件中包含了该数据库的各种属性,比方说该数据库的字符集和比较规则是个啥。
# 表在文件系统中的表示
我们的数据其实都是以记录的形式插入到表中的,每个表的信息其实可以分为两种:
- 表结构的定义
- 表中的数据
表结构 就是该表的名称是啥,表里边有多少列,每个列的数据类型是啥,有啥约束条件和索引,用的是啥字符集和比较规则吧啦吧啦的各种信息,这些信息都体现在了我们的建表语句中了。为了保存这些信息, InnoDB 和MyISAM 这两种存储引擎都在 数据目录 下对应的数据库子目录下创建了一个专门用于描述表结构的文件,文件名是这样:表名.frm
比方说我们在 mydb 数据库下创建一个名为 test 的表
mysql> USE mydb;
Database changedmysql
> CREATE TABLE test (
-> c1 INT
-> );
Query OK, 0 rows affected (0.03 sec)
那在数据库 mydb 对应的子目录下就会创建一个名为 test.frm 的用于描述表结构的文件
# InnoDB是如何存储表数据的
- InnoDB 其实是使用 页 为基本单位来管理存储空间的,默认的 页 大小为 16KB 。
- 对于 InnoDB 存储引擎来说,每个索引都对应着一棵 B+ 树,该 B+ 树的每个节点都是一个数据页,数据页之间不必要是物理连续的,因为数据页之间有 双向链表 来维护着这些页的顺序。
- InnoDB 的聚簇索引的叶子节点存储了完整的用户记录,也就是所谓的索引即数据,数据即索引。
为了更好的管理这些页,设计 InnoDB 的大叔们提出了一个 表空间 或者 文件空间 (英文名: table space 或者 file space )的概念,这个表空间是一个抽象的概念,它可以对应文件系统上一个或多个真实文件(不同表空间对应的文件数量可能不同)。每一个 表空间 可以被划分为很多很多很多个 页 ,我们的表数据就存放在某个 表空间 下的某些页里。
# 系统表空间(system tablespace)
这个所谓的 系统表空间 可以对应文件系统上一个或多个实际的文件,默认情况下, InnoDB 会在 数据目录 下创建一个名为 ibdata1 、大小为 12M 的文件,这个文件就是对应的 系统表空间 在文件系统上的表示。当不够用的时候它会自己增加文件大小~
需要注意的一点是,在一个MySQL服务器中,系统表空间只有一份。从MySQL5.5.7到MySQL5.6.6之间的各个版本中,我们表中的数据都会被默认存储到这个 系统表空间。
# 独立表空间(file-per-table tablespace)
在MySQL5.6.6以及之后的版本中, InnoDB 并不会默认的把各个表的数据存储到系统表空间中,而是为每一个表建立一个独立表空间,也就是说我们创建了多少个表,就有多少个独立表空间。使用 独立表空间 来存储表数据的话,会在该表所属数据库对应的子目录下创建一个表示该 独立表空间 的文件,文件名和表名相同,只不过添加了一个 .ibd 的扩展名而已,所以完整的文件名称长这样:表名.ibd
比方说假如我们使用了 独立表空间 去存储 mydb 数据库下的 test 表的话,那么在该表所在数据库对应的 mydb 目录下会为 test 表创建这两个文件:test.frm test.ibd
其中 test.ibd 文件就用来存储 test 表中的数据和索引。当然我们也可以自己指定使用 系统表空间 还是 独立表空间 来存储数据,这个功能由启动参数 innodbfilepertable 控制,比如说我们想刻意将表数据都存储到系统表空间 时,可以在启动 MySQL 服务器的时候这样配置:
[server]
innodbfilepertable=0
当 innodbfilepertable 的值为 0/OFF时,代表使用系统表空间; 当 innodbfilepertable 的值为 1/ON 时,代表使用独立表空间。 不过 innodbfilepertable 参数只对新建的表起作用,对于已经分配了表空间的表并不起作用。 如果我们想把已经存在系统表空间中的表转移到独立表空间,可以使用下边的语法:其中中括号扩起来的 = 可有可无
ALTER TABLE 表名 TABLESPACE [=] innodbfilepertable;
或者把已经存在独立表空间的表转移到系统表空间,可以使用下边的语法:
ALTER TABLE 表名 TABLESPACE [=] innodbsystem;
# MyISAM是如何存储表数据的
在 MyISAM 中的索引全部都是 二级索引 ,该存储引擎的数据和索引是分开存放的。所以在文件系统中也是使用不同的文件来存储数据文件和索引文件。而且和 InnoDB 不同的是, MyISAM 并没有什么所谓的 表空间 一说,表数据都存放到对应的数据库子目录下。 test.frm test.MYD test.MYI 其中 test.MYD 代表表的数据文件,也就是我们插入的用户记录; test.MYI 代表表的索引文件,我们为该表创建的索引都会放到这个文件中。
# InnoDB的表空间
表空间 是一个抽象的概念,对于系统表空间来说,对应着文件系统中一个或多个实际文件;对于每个独立表空间来说,对应着文件系统中一个名为 表名.ibd 的实际文件。大家可以把表空间想 象成被切分为许许多多个 页 的池子,当我们想为某个表插入一条记录的时候,就从池子中捞出一个对应的页来 把数据写进去。

# 页面类型
数据页的类型名其实 是: FIL_PAGE_INDEX ,除了这种存放索引数据的页面类型之外,InnoDB也为了不同的目的设计了若干种不同类 型的页面
| 类型名称 | 十六进制 | 描述 |
|---|---|---|
| FIL_PAGE_TYPE_ALLOCATED | 0x0000 | 最新分配,还没使用 |
| FIL_PAGE_UNDO_LOG | 0x0002 | Undo日志页 |
| FIL_PAGE_INODE | 0x0003 | 段信息节点 |
| FIL_PAGE_IBUF_FREE_LIST | 0x0004 | Insert Buffer空闲列表 |
| FIL_PAGE_IBUF_BITMAP | 0x0005 | Insert Buffer位图 |
| FIL_PAGE_TYPE_SYS | 0x0006 | 系统页 |
| FIL_PAGE_TYPE_TRX_SYS | 0x0007 | 事务系统数据 |
| FIL_PAGE_TYPE_FSP_HDR | 0x0008 | 表空间头部信息 |
| FIL_PAGE_TYPE_XDES | 0x0009 | 扩展描述页 |
| FIL_PAGE_TYPE_BLOB | 0x000A | BLOB页 |
| FIL_PAGE_INDEX | 0x45BF | 索引页,也就是我们所说的数据页 |
# 页面通用部分
数据页,也就是 INDEX 类型的页由7个部分组成,其中的两个部分是所有类型的页面都通用的
 任何类型的页都会包含这两个部分:
任何类型的页都会包含这两个部分:
- File Header :记录页面的一些通用信息
- File Trailer :校验页是否完整,保证从内存到磁盘刷新时内容的一致性。
# File Header 组成部分
| 名称 | 占用空间大小 | 描述 |
|---|---|---|
| FIL_PAGE_SPACE_OR_CHKSUM | 4 字节 | 页的校验和(checksum值) |
| FIL_PAGE_OFFSET | 4 字节 | 页号 |
| FIL_PAGE_PREV | 4 字节 | 上一个页的页号 |
| FIL_PAGE_NEXT | 4 字节 | 下一个页的页号 |
| FIL_PAGE_LSN | 8 字节 | 页面被最后修改时对应的日志序列位置(英文名是:Log SequenceNumber) |
| FIL_PAGE_TYPE | 2 字节 | 该页的类型 |
| FIL_PAGE_FILE_FLUSH_LSN | 8 字节 | 仅在系统表空间的一个页中定义,代表文件至少被刷新到了对应的LSN值 |
| FIL_PAGE_ARCH_LOG_NO_OR_SPACE_ID | 4 字节 | 页属于哪个表空间 |
- 表空间中的每一个页都对应着一个页号,也就是 FIL_PAGE_OFFSET ,这个页号由4个字节组成,也就是32个 比特位,所以一个表空间最多可以拥有2³²个页,如果按照页的默认大小16KB来算,一个表空间最多支持 64TB的数据。表空间的第一个页的页号为0,之后的页号分别是1,2,3...依此类推
- 某些类型的页可以组成链表,链表中的页可以不按照物理顺序存储,而是根据 FIL_PAGE_PREV 和
FIL_PAGE_NEXT 来存储上一个页和下一个页的页号。需要注意的是,这两个字段主要是为了 INDEX 类型的 页,也就是我们之前一直说的数据页建立 B+ 树后,为每层节点建立双向链表用的,一般类型的页是不使用 这两个字段的。
- 每个页的类型由 FIL_PAGE_TYPE 表示,比如像数据页的该字段的值就是 0x45BF ,我们后边会介绍各种不同 类型的页,不同类型的页在该字段上的值是不同的。
# 独立表空间结构
# 区(extent)的概念
表空间中的页实在是太多了,为了更好的管理这些页面,设计 InnoDB 的大叔们提出了 区 (英文名: extent ) 的概念。对于16KB的页来说,连续的64个页就是一个 区 ,也就是说一个区默认占用1MB空间大小。不论是系统 表空间还是独立表空间,都可以看成是由若干个区组成的,每256个区被划分成一组。画个图表示就是这样:
 这些组的头几个页面的类型都是类似的:
这些组的头几个页面的类型都是类似的:

- 第一个组最开始的3个页面的类型是固定的,也就是说 extent 0 这个区最开始的3个页面的类型是固定的,
分别是:
- FSP_HDR 类型:这个类型的页面是用来登记整个表空间的一些整体属性以及本组所有的 区 ,也就是
extent 0 ~ extent 255 这256个区的属性,稍后详细唠叨。需要注意的一点是,整个表空间只有一个 FSP_HDR 类型的页面。
- IBUF_BITMAP 类型:这个类型的页面是存储本组所有的区的所有页面关于 INSERT BUFFER 的信息。
- INODE 类型:这个类型的页面存储了许多称为 INODE 的数据结构
- 其余各组最开始的2个页面的类型是固定的,也就是说 extent 256 、 extent 512 这些区最开始的2个页面 的类型是固定的,分别是:
- XDES 类型:全称是 extent descriptor ,用来登记本组256个区的属性,也就是说对于在 extent 256 区中的该类型页面存储的就是 extent 256 ~ extent 511 这些区的属性,对于在 extent 512 区中的该
类型页面存储的就是 extent 512 ~ extent 767 这些区的属性。上边介绍的 FSP_HDR 类型的页面其实 和 XDES 类型的页面的作用类似,只不过 FSP_HDR 类型的页面还会额外存储一些表空间的属性。
- IBUF_BITMAP 类型:上边介绍过了。
# 段(segment)的概念
一个区就是在物理位置上连续的64个页。
存放叶子节点的区的集合就算是一个 段( segment ),存放非叶子节点的区的集合也算是一个 段 。也就是说一个索引会生成2个段,一个叶子节点段,一个非叶子节点段。
现在为了考虑以完整的区为单位分配给某个段对于数据量较小的表太浪费存储空间的这种情况,设计 InnoDB 的大叔们提出了一个碎片(fragment) 区的概念,也就是在一个碎片区中,并不是所有的页都是为了存储同一个段的数据而存在的,而是碎片区中的页 可以用于不同的目的,比如有些页用于段A,有些页用于段B,有些页甚至哪个段都不属于。 碎片区直属于表空间,并不属于任何一个段。所以此后为某个段分配存储空间的策略是这样的:
- 在刚开始向表中插入数据的时候,段是从某个碎片区以单个页面为单位来分配存储空间的。
- 当某个段已经占用了32个碎片区页面之后,就会以完整的区为单位来分配存储空间。
段是一些零散的页面以及一些完整的区的集合
# 区的分类
区大体上可以分为4种类型:
- 空闲的区:现在还没有用到这个区中的任何页面。
- 有剩余空间的碎片区:表示碎片区中还有可用的页面。
- 没有剩余空间的碎片区:表示碎片区中的所有页面都被使用,没有空闲页面。
- 附属于某个段的区。每一个索引都可以分为叶子节点段和非叶子节点段,除此之外InnoDB还会另外定义一些 特殊作用的段,在这些段中的数据量很大时将使用区来作为基本的分配单位。
这4种类型的区也可以被称为区的4种状态( State ),设计 InnoDB 的大叔们为这4种状态的区定义了特定的名 词儿:
| 状态名 | 含义 |
|---|---|
| FREE | 空闲的区 |
| FREE_FRAG | 有剩余空间的碎片区 |
| FULL_FRAG | 没有剩余空间的碎片区 |
| FSEG | 附属于某个段的区 |
需要再次强调一遍的是,处于 FREE 、 FREE_FRAG 以及 FULL_FRAG 这三种状态的区都是独立的,算是直属于表空间;而处于 FSEG 状态的区是附属于某个段的。
小贴士:
如果把表空间比作是一个集团军,段就相当于师,区就相当于团。一般的团都是隶属于某个师的,就像 是处于FSEG的区全都隶属于某个段,而处于FREE、FREE_FRAG以及FULL_FRAG这三种状态的区却 直接隶属于表空间,就像独立团直接听命于军部一样。
 为了方便管理这些区,设计 InnoDB 的大叔设计了一个称为 XDES Entry 的结构(全称就是Extent Descriptor Entry),每一个区都对应着一个 XDES Entry 结构,这个结构记录了对应的区的一些属性。我们先看图来对这个 结构有个大致的了解:
为了方便管理这些区,设计 InnoDB 的大叔设计了一个称为 XDES Entry 的结构(全称就是Extent Descriptor Entry),每一个区都对应着一个 XDES Entry 结构,这个结构记录了对应的区的一些属性。我们先看图来对这个 结构有个大致的了解:
 XDES Entry 是一个40个字节的结构,大致分为4个部分
XDES Entry 是一个40个字节的结构,大致分为4个部分
- Segment ID (8字节)
每一个段都有一个唯一的编号,用ID表示,此处的 Segment ID 字段表示就是该区所在的段。当然前提是该 区已经被分配给某个段了,不然的话该字段的值没啥意义。
- List Node (12字节)
这个部分可以将若干个 XDES Entry 结构串联成一个链表,大家看一下这个 List Node 的结构:
 如果我们想定位表空间内的某一个位置的话,只需指定页号以及该位置在指定页号中的页内偏移量即可。所 以:
如果我们想定位表空间内的某一个位置的话,只需指定页号以及该位置在指定页号中的页内偏移量即可。所 以:
- Pre Node Page Number 和 Pre Node Offset 的组合就是指向前一个 XDES Entry 的指针
- Next Node Page Number 和 Next Node Offset 的组合就是指向后一个 XDES Entry 的指针。
- State (4字节)
这个字段表明区的状态。可选的值就是我们前边说过的那4个,分别是: FREE 、 FREE_FRAG 、 FULL_FRAG 和 FSEG 。
- Page State Bitmap (16字节)
这个部分共占用16个字节,也就是128个比特位。我们说一个区默认有64个页,这128个比特位被划分为64 个部分,每个部分2个比特位,对应区中的一个页。比如 Page State Bitmap 部分的第1和第2个比特位对应 着区中的第1个页面,第3和第4个比特位对应着区中的第2个页面,依此类推, Page State Bitmap 部分的第 127和128个比特位对应着区中的第64个页面。这两个比特位的第一个位表示对应的页是否是空闲的,第二个 比特位还没有用。
# XDES Entry链表
- 当段中数据较少的时候,首先会查看表空间中是否有状态为 FREE_FRAG 的区,也就是找还有空闲空间的碎片 区,如果找到了,那么从该区中取一些零碎的页把数据插进去;否则到表空间下申请一个状态为 FREE 的 区,也就是空闲的区,把该区的状态变为 FREE_FRAG ,然后从该新申请的区中取一些零碎的页把数据插进 去。之后不同的段使用零碎页的时候都会从该区中取,直到该区中没有空闲空间,然后该区的状态就变成了
FULL_FRAG 。
那如何知道那些区是 FREE,FREE_FRAG,FULL_FRAG呢?
- 把状态为 FREE 的区对应的 XDES Entry 结构通过 List Node 来连接成一个链表,这个链表我们就称之 为 FREE 链表。
- 把状态为 FREE_FRAG 的区对应的 XDES Entry 结构通过 List Node 来连接成一个链表,这个链表我们就 称之为 FREE_FRAG 链表。
- 把状态为 FULL_FRAG 的区对应的 XDES Entry 结构通过 List Node 来连接成一个链表,这个链表我们就 称之为 FULL_FRAG 链表。
上面的三个链表直属于表空间 这样每当我们想找一个 FREE_FRAG 状态的区时,就直接把 FREE_FRAG 链表的头节点拿出来,从这个节点中取一些零碎的页来插入数据,当这个节点对应的区用完时,就修改一下这个节点的 State 字段的值, 然后从 FREE_FRAG 链表中移到 FULL_FRAG 链表中。同理,如果 FREE_FRAG 链表中一个节点都没有,那 么就直接从 FREE 链表中取一个节点移动到 FREE_FRAG 链表的状态,并修改该节点的 STATE 字段值为 FREE_FRAG ,然后从这个节点对应的区中获取零碎的页就好了。
- 当段中数据已经占满了32个零散的页后,就直接申请完整的区来插入数据了。
每个段中的区对应的 XDES Entry 结构建立了三个链表:
- FREE 链表:同一个段中,所有页面都是空闲的区对应的 XDES Entry 结构会被加入到这个链表。注意和
直属于表空间的 FREE 链表区别开了,此处的 FREE 链表是附属于某个段的。
- NOT_FULL 链表:同一个段中,仍有空闲空间的区对应的 XDES Entry 结构会被加入到这个链表。
- FULL 链表:同一个段中,已经没有空闲空间的区对应的 XDES Entry 结构会被加入到这个链表
这三个链表在每个段上都有 每一个索引都对应两个段,每个段都会维护上述的3个链表,比如下边这个表:
CREATE TABLE t (
c1 INT NOT NULL AUTO_INCREMENT,
c2 VARCHAR(100),
c3 VARCHAR(100),
PRIMARY KEY (c1),
KEY idx_c2 (c2)
)ENGINE=InnoDB;
这个表 t 共有两个索引,一个聚簇索引,一个二级索引 idx_c2 ,所以这个表共有4个段,每个段都会维护上述3个链表,总共是12个链表,加上我们上边说过的直属于表空间的3个链表,整个独立表空间共 需要维护15个链表。所以段在数据量比较大时插入数据的话,会先获取 NOT_FULL 链表的头节点,直接把数据插入这个头节点对应的区中即可,如果该区的空间已经被用完,就把该节点移到 FULL 链表中。
# 链表基节点
这个结构中包含了链表的头节点和尾节点的指针以及这个链表中包含了多少节点的信息
 我们上边介绍的每个链表都对应这么一个 List Base Node 结构,其中:
我们上边介绍的每个链表都对应这么一个 List Base Node 结构,其中:
- List Length 表明该链表一共有多少节点,
- First Node Page Number 和 First Node Offset 表明该链表的头节点在表空间中的位置。
- Last Node Page Number 和 Last Node Offset 表明该链表的尾节点在表空间中的位置。
一般我们把某个链表对应的 List Base Node 结构放置在表空间中固定的位置,这样想找定位某个链表就变得so easy啦。
# 链表小结
综上所述,表空间是由若干个区组成的,每个区都对应一个 XDES Entry 的结构
- 直属于表空间的区对应的 XDES Entry 结构可以分成 FREE 、 FREE_FRAG 和 FULL_FRAG 这3个链表;
- 每个段可以附属若干个区,每个段中的区对应的 XDES Entry 结构可以分成 FREE 、 NOT_FULL 和 FULL 这3个链表。
- 每个链表都对应一个 List Base Node 的 结构,这个结构里记录了链表的头、尾节点的位置以及该链表中包含的节点数。
正是因为这些链表的存在,管理 这些区才变成了一件so easy的事情。
# 段的结构
我们前边说过,段其实不对应表空间中某一个连续的物理区域,而是一个逻辑上的概念,由若干个零散的页面以 及一些完整的区组成。像每个区都有对应的 XDES Entry 来记录这个区中的属性一样,设计 InnoDB 的大叔为每个段都定义了一个 INODE Entry 结构来记录一下段中的属性。
 它的各个部分释义如下:
它的各个部分释义如下:
- Segment ID
就是指这个 INODE Entry 结构对应的段的编号(ID)。
- NOT_FULL_N_USED
这个字段指的是在 NOT_FULL 链表中已经使用了多少个页面。下次从 NOT_FULL 链表分配空闲页面时可以直接根据这个字段的值定位到。而不用从链表中的第一个页面开始遍历着寻找空闲页面。
- 3个 List Base Node
分别为段的 FREE 链表、 NOT_FULL 链表、 FULL 链表,定义了 List Base Node ,这样我们想查找某个段的某 个链表的头节点和尾节点的时候,就可以直接到这个部分找到对应链表的 List Base Node 。so easy!
- Magic Number :
这个值是用来标记这个 INODE Entry 是否已经被初始化了(初始化的意思就是把各个字段的值都填进去 了)。如果这个数字是值的 97937874 ,表明该 INODE Entry 已经初始化,否则没有被初始化。(不用纠结 这个值有啥特殊含义,人家规定的)。
- Fragment Array Entry
我们前边强调过无数次段是一些零散页面和一些完整的区的集合,每个 Fragment Array Entry 结构都对应 着一个零散的页面,这个结构一共4个字节,表示一个零散页面的页号。 结合着这个 INODE Entry 结构,大家可能对段是一些零散页面和一些完整的区的集合的理解再次深刻一些。
# 各类型页面详细情况
# FSP_HDR 类型
首先看第一个组的第一个页面,当然也是表空间的第一个页面,页号为 0 。这个页面的类型是 FSP_HDR ,它存储 了表空间的一些整体属性以及第一个组内256个区的对应的 XDES Entry 结构
 从图中可以看出,一个完整的 FSP_HDR 类型的页面大致由5个部分组成,各个部分的具体释义如下表:
从图中可以看出,一个完整的 FSP_HDR 类型的页面大致由5个部分组成,各个部分的具体释义如下表:
| 名称 | 中文名 | 占用空间大小 | _简单描述 _ |
|---|---|---|---|
| File Header | 文件头部 | 38 字节 | 页的一些通用信息 |
| File Space Header | 表空间头部 | 112 字节 | 表空间的一些整体属性信息 |
| XDES Entry | 区描述信息 | 10240 字节 | 存储本组256个区对应的属性信息 |
| Empty Space | 尚未使用空间 | 5986 字节 | 用于页结构的填充,没啥实际意义 |
| File Trailer | 文件尾部 | 8 字节 | 校验页是否完整 |
File Header 和 File Trailer 就不再强调了,另外的几个部分中, Empty Space 是尚未使用的空间,我们不用 管它,重点来看看 File Space Header 和 XDES Entry 这两个部分。
**File Space Header部分 **

| 名称 | 大小 | 描述 |
|---|---|---|
| Space ID | 4 字节 | 表空间的ID |
| Not Used | 4 字节 | 这4个字节未被使用,可以忽略 |
| Size | 4 字节 | 当前表空间占有的页面数 |
| FREE Limit | 4 字节 | 尚未被初始化的最小页号,大于或等于这个页号的区对应的XDES Entry结构都没有被加入FREE链表 |
| Space Flags | 4 字节 | 表空间的一些占用存储空间比较小的属性 |
| FRAG_N_USED | 4 字节 | FREE_FRAG链表中已使用的页面数量 |
| List Base Node for FREE List | 16 字节 | FREE链表的基节点 |
| List Base Node for FREE_FRAG List | 16 字节 | FREE_FREG链表的基节点 |
| List Base Node for FULL_FRAG List | 16 字节 | FULL_FREG链表的基节点 |
| Next Unused Segment ID | 8 字节 | 当前表空间中下一个未使用的 Segment ID |
| List Base Node for SEG_INODES_FULL List | 16 字节 | SEG_INODES_FULL链表的基节点 |
| List Base Node for SEG_INODES_FREE List | 16 字节 | SEG_INODES_FREE链表的基节点 |
XDES Entry部分 我们知道一个 XDES Entry 结构的大小是40字节,但是一个页面的大小有限,只能存放有限个 XDES Entry 结构,所以我们才把256个区划分成一组,在每组的第一个页面中存放 256个 XDES Entry 结构。大家回看那个 FSP_HDR 类型页面的示意图, XDES Entry 0 就对应着 extent 0 , XDES Entry 1 就对应着 extent 1 ... 依此类推, XDES Entry255 就对应着 extent 255 。
# XDES 类型
除去第一个分组以外,之后的每个分组的第一个页面只需要记录本组内所有的区对应的 XDES Entry 结构即可,不需要再记录表空间的属性了,为了和 FSP_HDR 类型做区别,我们把之后每个分组的第一个页面的类型定义为 XDES
 与 FSP_HDR 类型的页面对比,除了少了 File Space Header 部分之外,也就是除了少了记录表空间整体属性的部分之外,其余的部分是一样一样的。
与 FSP_HDR 类型的页面对比,除了少了 File Space Header 部分之外,也就是除了少了记录表空间整体属性的部分之外,其余的部分是一样一样的。
IBUF_BITMAP 类型 对比前边介绍表空间的图,每个分组的第二个页面的类型都是 IBUF_BITMAP ,这种类型的页里边记录了一些有 关 Change Buffer 的东东
INODE 类型
再次对比前边介绍表空间的图,第一个分组的第三个页面的类型是 INODE 。我们前边说过设计 InnoDB 的大叔为每个索引定义了两个段,而且为某些特殊功能定义了些特殊的段。为了方便管理,他们又为每个段设计了一个
INODE Entry 结构,这个结构中记录了关于这个段的相关属性。而我们这会儿要介绍的这个 INODE 类型的页就是为了存储 INODE Entry 结构而存在的

| 名称 | 中文名 | 占用空间大小 | 简单描述 |
|---|---|---|---|
| File Header | 文件头部 | 38 字节 | 页的一些通用信息 |
| List Node for INODE Page List | 通用链表节点 | 12 字节 | 存储上一个INODE页面和下一个INODE页面的指针 |
| INODE Entry | 段描述信息 | 16128 字节 | |
| Empty Space | 尚未使用空间 | 6 字节 | 用于页结构的填充,没啥实际意义 |
| File Trailer | 文件尾部 | 8 字节 | 校验页是否完整 |
首先看 INODE Entry 部分,我们前边已经详细介绍过这个结构的组成了,主要包括对应的段内零散页面的地址以 及附属于该段的 FREE 、 NOT_FULL 和 FULL 链表的基节点。每个 INODE Entry 结构占用192字节,一个页面里可 以存储 85 个这样的结构。
因为一个表空间中可能存在超过85个段,所以可能一 个 INODE 类型的页面不足以存储所有的段对应的 INODE Entry 结构,所以就需要额外的 INODE 类型的页面来存 储这些结构。还是为了方便管理这些 INODE 类型的页面,设计 InnoDB 的大叔们将这些 INODE 类型的页面串联成 两个不同的链表:
- SEG_INODES_FULL 链表:该链表中的 INODE 类型的页面中已经没有空闲空间来存储额外的 INODE Entry 结 构了。
- SEG_INODES_FREE 链表:该链表中的 INODE 类型的页面中还有空闲空间来存储额外的 INODE Entry 结构 了。
想必大家已经认出这两个链表了,我们前边提到过这两个链表的基节点就存储在 File Space Header 里边,也就 是说这两个链表的基节点的位置是固定的,所以我们可以很轻松的访问到这两个链表。以后每当我们新创建一个 段(创建索引时就会创建段)时,都会创建一个 INODE Entry 结构与之对应,存储 INODE Entry 的大致过程就是 这样的:
- 先看看 SEG_INODES_FREE 链表是否为空,如果不为空,直接从该链表中获取一个节点,也就相当于获取到一 个仍有空闲空间的 INODE 类型的页面,然后把该 INODE Entry 结构防到该页面中。当该页面中无剩余空间 时,就把该页放到 SEG_INODES_FULL 链表中。
- 如果 SEG_INODES_FREE 链表为空,则需要从表空间的 FREE_FRAG 链表中申请一个页面,修改该页面的类型 为 INODE ,把该页面放到 SEG_INODES_FREE 链表中,与此同时把该 INODE Entry 结构放入该页面。
# Segment Header 结构的运用
我们知道一个索引会产生两个段,分别是叶子节点段和非叶子节点段,而每个段都会对应一个 INODE Entry 结构,那我们怎么知道某个段对应哪个 INODE Entry 结构呢?所以得找个地方记下来这个对应关系。希望你还记得 我们在唠叨数据页,也就是 INDEX 类型的页时有一个 Page Header 部分,当然我不能指望你记住,所以把 Page Header 部分再抄一遍给你看:
| 名称 | 占用空间大小 | 描述 |
|---|---|---|
| PAGE_BTR_SEG_LEAF | 10 字节 | B+树叶子段的头部信息,仅在B+树的根页定义 |
| PAGE_BTR_SEG_TOP | 10 字节 | B+树非叶子段的头部信息,仅在B+树的根页定义 |
其中的 PAGE_BTR_SEG_LEAF 和 PAGE_BTR_SEG_TOP 都占用10个字节,它们其实对应一个叫 Segment Header 的结 构,该结构图示如下:

| 名称 | 占用字节数 | 描述 |
|---|---|---|
| Space ID of the INODE Entry | 4 | INODE Entry结构所在的表空间ID |
| Page Number of the INODE Entry | 4 | INODE Entry结构所在的页面页号 |
| Byte Offset of the INODE Ent | 2 | INODE Entry结构在该页面中的偏移量 |
PAGE_BTR_SEG_LEAF 记录着叶子节点段对应的 INODE Entry 结构的地址是哪个表空间的哪个 页面的哪个偏移量, PAGE_BTR_SEG_TOP 记录着非叶子节点段对应的 INODE Entry 结构的地址是哪个表空间的哪 个页面的哪个偏移量。这样子索引和其对应的段的关系就建立起来了。不过需要注意的一点是,因为一个索引只 对应两个段,所以只需要在索引的根页面中记录这两个结构即可。
# 系统表空间
了解完了独立表空间的基本结构,系统表空间的结构也就好理解多了,系统表空间的结构和独立表空间基本类似,只不过由于整个MySQL进程只有一个系统表空间,在系统表空间中会额外记录一些有关整个系统信息的页面,所以会比独立表空间多出一些记录这些信息的页面。因为这个系统表空间最牛逼,相当于是表空间之首,所 以它的 表空间 ID (Space ID)是 0 。
# 系统表空间的整体结构
 可以看到,系统表空间和独立表空间的前三个页面(页号分别为 0 、 1 、 2 ,类型分别是 FSP_HDR 、 IBUF_BITMAP 、 INODE )的类型是一致的,只是页号为 3 ~ 7 的页面是系统表空间特有的
可以看到,系统表空间和独立表空间的前三个页面(页号分别为 0 、 1 、 2 ,类型分别是 FSP_HDR 、 IBUF_BITMAP 、 INODE )的类型是一致的,只是页号为 3 ~ 7 的页面是系统表空间特有的
| 页号 | _ 页面类型_ | _ 英文描述_ | _ 描述_ |
|---|---|---|---|
| 3 | SYS | Insert Buffer Header | 存储Insert Buffer的头部信息 |
| 4 | INDEX | Insert Buffer Root | 存储Insert Buffer的根页面 |
| 5 | TRX_SYS | Transction System | 事务系统的相关信息 |
| 6 | SYS | First Rollback Segment | 第一个回滚段的页面 |
| 7 | SYS | Data Dictionary Header | 数据字典头部信息 |
除了这几个记录系统属性的页面之外,系统表空间的 extent 1 和 extent 2 这两个区,也就是页号从 64 ~ 191 这128个页面被称为 Doublewrite buffer ,也就是双写缓冲区。不过上述的大部分知识都涉及到了事务和多版本控制的问题
# InnoDB数据字典
所以说,MySQL 除了保存着我们插入的用户数据之外,还需要保存许多额外的信息,比方说:
- 某个表属于哪个表空间,表里边有多少列
- 表对应的每一个列的类型是什么
- 该表有多少索引,每个索引对应哪几个字段,该索引对应的根页面在哪个表空间的哪个页面
- 该表有哪些外键,外键对应哪个表的哪些列
- 某个表空间对应文件系统上文件路径是什么
上述这些数据并不是我们使用 INSERT 语句插入的用户数据,实际上是为了更好的管理我们这些用户数据而不得已引入的一些额外数据,这些数据也称为 元数据 。InnoDB存储引擎特意定义了一些列的内部系统表(internal system table)来记录这些这些 元数据 :
| 表名 | 描述 |
|---|---|
| SYS_TABLES | 整个InnoDB存储引擎中所有的表的信息 |
| SYS_COLUMNS | 整个InnoDB存储引擎中所有的列的信息 |
| SYS_INDEXES | 整个InnoDB存储引擎中所有的索引的信息 |
| SYS_FIELDS | 整个InnoDB存储引擎中所有的索引对应的列的信息 |
| SYS_FOREIGN | 整个InnoDB存储引擎中所有的外键的信息 |
| SYS_FOREIGN_COLS | 整个InnoDB存储引擎中所有的外键对应列的信息 |
| SYS_TABLESPACES | 整个InnoDB存储引擎中所有的表空间信息 |
| SYS_DATAFILES | 整个InnoDB存储引擎中所有的表空间对应文件系统的文件路径信息 |
| SYS_VIRTUAL | 整个InnoDB存储引擎中所有的虚拟生成列的信息 |
这些系统表也被称为 数据字典 ,它们都是以 B+ 树的形式保存在系统表空间的某些页面中,其中 SYS_TABLES 、 SYS_COLUMNS 、 SYS_INDEXES 、 SYS_FIELDS 这四个表尤其重要,称之为基本系统表(basic system tables),我们先看看这4个表的结构:
SYS_TABLES表
| 列名 | 描述 |
|---|---|
| NAME | 表的名称 |
| ID | InnoDB存储引擎中每个表都有一个唯一的ID N_COLS 该表拥有列的个数 |
| TYPE | 表的类型,记录了一些文件格式、行格式、压缩等信息 MIX_ID 已过时,忽略 |
| MIX_LEN | 表的一些额外的属性 |
| CLUSTER_ID | 未使用,忽略 |
| SPACE | 该表所属表空间的ID |
这个 SYS_TABLES 表有两个索引:
- 以 NAME 列为主键的聚簇索引
- 以 ID 列建立的二级索引
SYS_COLUMNS表
| 列名 | 描述 |
|---|---|
| TABLE_ID | 该列所属表对应的ID |
| POS | 该列在表中是第几列 |
| NAME | 该列的名称 |
| MTYPE | main data type,主数据类型,就是那堆INT、CHAR、VARCHAR、FLOAT、DOUBLE之类的东东 PRTYPE precise type,精确数据类型,就是修饰主数据类型的那堆东东,比如是否允许NULL值,是否允许负数啥的 |
| LEN | 该列最多占用存储空间的字节数 |
| PREC | 该列的精度,不过这列貌似都没有使用,默认值都是0 |
这个 SYS_COLUMNS 表只有一个聚集索引:
- 以(TABLE_ID, POS) 列为主键的聚簇索引
SYS_INDEXES表
| 列名 | 描述 |
|---|---|
| TABLE_ID | 该索引所属表对应的ID |
| ID | |
| NAME | 该索引的名称 |
| N_FIELDS | 该索引包含列的个数 |
| TYPE | 该索引的类型,比如聚簇索引、唯一索引、更改缓冲区的索引、全文索引、普通的二级索引等等各种类型 SPACE 该索引根页面所在的表空间ID |
| PAGE_NO | 该索引根页面所在的页面号 |
| MERGE_THRESHOLD | 如果页面中的记录被删除到某个比例,就把该页面和相邻页面合并,这个值就是这个比例 |
这个 SYS_INEXES 表只有一个聚集索引:
- 以(TABLE_ID, ID) 列为主键的聚簇索引
SYS_FIELDS表
| 列名 | 描述 |
|---|---|
| INDEX_ID | 该索引列所属的索引的ID |
| POS | 该索引列在某个索引中是第几列 |
| COL_NAME | 该索引列的名称 |
这个 SYS_INEXES 表只有一个聚集索引:
- 以(INDEX_ID, POS) 列为主键的聚簇索引
**Data Dictionary Header页面 ** 只要有了上述4个基本系统表,也就意味着可以获取其他系统表以及用户定义的表的所有元数据。比方说我们想 看看 SYS_TABLESPACES 这个系统表里存储了哪些表空间以及表空间对应的属性,那就可以:
- 到 SYS_TABLES 表中根据表名定位到具体的记录,就可以获取到 SYS_TABLESPACES 表的 TABLE_ID
- 使用这个 TABLE_ID 到 SYS_COLUMNS 表中就可以获取到属于该表的所有列的信息。
- 使用这个 TABLE_ID 还可以到 SYS_INDEXES 表中获取所有的索引的信息,索引的信息中包括对应的INDEX_ID ,还记录着该索引对应的 B+ 数根页面是哪个表空间的哪个页面。
- 使用 INDEX_ID 就可以到 SYS_FIELDS 表中获取所有索引列的信息。
也就是说这4个表是表中之表,那这4个表的元数据去哪里获取呢?没法搞了,只能把这4个表的元数据,就是它 们有哪些列、哪些索引等信息硬编码到代码中,然后设计 InnoDB 的大叔又拿出一个固定的页面来记录这4个表的 聚簇索引和二级索引对应的 B+树 位置,这个页面就是页号为 7 的页面,类型为 SYS ,记录了 Data Dictionary Header ,也就是数据字典的头部信息。除了这4个表的5个索引的根页面信息外,这个页号为 7 的页面还记录了 整个InnoDB存储引擎的一些全局属性

# 总体图

# 单表访问方法
测试表
CREATE TABLE single_table (
id INT NOT NULL AUTO_INCREMENT,
key1 VARCHAR(100),
key2 INT,
key3 VARCHAR(100),
key_part1 VARCHAR(100),
key_part2 VARCHAR(100),
key_part3 VARCHAR(100),
common_field VARCHAR(100),
PRIMARY KEY (id),
KEY idx_key1 (key1),
UNIQUE KEY idx_key2 (key2),
KEY idx_key3 (key3),
KEY idx_key_part(key_part1, key_part2, key_part3)
) Engine=InnoDB CHARSET=utf8;
我们为这个 single_table 表建立了1个聚簇索引和4个二级索引,分别是:
- 为 id 列建立的聚簇索引。
- 为 key1 列建立的 idx_key1 二级索引。
- 为 key2 列建立的 idx_key2 二级索引,而且该索引是唯一二级索引。
- 为 key3 列建立的 idx_key3 二级索引。
- 为 key_part1 、 key_part2 、 key_part3 列建立的 idx_key_part 二级索引,这也是一个联合索引。
然后我们需要为这个表插入10000行记录,除 id 列外其余的列都插入随机值就好了
# 删除存储过程
drop procedure single_table_insert;
# 创建存储过程
create procedure single_table_insert()
begin
declare i int default 1;
while i <= 10000
do
insert into test_db.single_table(key1, key2, key3, key_part1, key_part2, key_part3, common_field)
values (
md5(rand()),
CEILING(RAND()*900000000+100000000),
md5(rand()),
md5(rand()),
md5(rand()),
md5(rand()),
md5(rand())
);
set i = i + 1;
end while;
end;
# 执行存储过程
call single_table_insert();
设计 MySQL 的大叔把 MySQL 执行查询语句的方式称之为 访问方法 或者 访问类型 。同一个查询语句可能可以使 用多种不同的访问方法来执行,虽然最后的查询结果都是一样的,但是执行的时间可能差老鼻子远了
https://dev.mysql.com/doc/refman/5.7/en/explain-output.html#jointype_const (opens new window)
# const
该表最多有一个匹配的行,在查询开始时读取。因为只有一行,所以这一行中的列值可以被优化器的其他部分视为常量。Const表非常快,因为它们只被读取一次。
const用于将 PRIMARY KEY或 UNIQUE索引的所有部分与常量值进行比较。在以下查询都的type都是const
primary key
mysql> explain select * from single_table where id = 10;
+----+-------------+--------------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| 1 | SIMPLE | single_table | NULL | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | NULL |
+----+-------------+--------------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.03 sec)
unique not null
mysql> explain select * from single_table where key2 = 604984347;
+----+-------------+--------------+------------+-------+---------------+----------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------------+------------+-------+---------------+----------+---------+-------+------+----------+-------+
| 1 | SIMPLE | single_table | NULL | const | idx_key2 | idx_key2 | 5 | const | 1 | 100.00 | NULL |
+----+-------------+--------------+------------+-------+---------------+----------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.02 sec)
 对于唯一二级索引来说,查询该列为 NULL 值的情况比较特殊,比如这样:
对于唯一二级索引来说,查询该列为 NULL 值的情况比较特殊,比如这样:
SELECT * FROM single_table WHERE key2 IS NULL;
因为唯一二级索引列并不限制 NULL 值的数量,所以上述语句可能访问到多条记录,也就是说 上边这个语句不可以使用 const 访问方法来执行
# ref
有时候我们对某个普通的二级索引列与常数进行等值比较,比如这样:
mysql> explain select * from single_table where key1 = 'abc';
+----+-------------+--------------+------------+------+---------------+----------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------------+------------+------+---------------+----------+---------+-------+------+----------+-------+
| 1 | SIMPLE | single_table | NULL | ref | idx_key1 | idx_key1 | 303 | const | 1 | 100.00 | NULL |
+----+-------------+--------------+------------+------+---------------+----------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.01 sec)
由于普通二级索引并不限制索引列值的唯一 性,所以可能找到多条对应的记录,也就是说使用二级索引来执行查询的代价取决于等值匹配到的二级索引记录条数。设计 MySQL 的大叔就把这种搜索条件为二级索引列与常数等值比较,采用二级索引来执行查询的访问方法称为: ref

- 二级索引列值为 NULL 的情况
不论是普通的二级索引,还是唯一二级索引,它们的索引列对包含 NULL 值的数量并不限制,所以我们采用key IS NULL 这种形式的搜索条件最多只能使用 ref 的访问方法,而不是 const 的访问方法。
- 对于某个包含多个索引列的二级索引来说,只要是最左边的连续索引列是与常数的等值比较就可能采用 ref 的访问方法,比方说下边这几个查询:
SELECT * FROM single_table WHERE key_part1 = 'god like';
SELECT * FROM single_table WHERE key_part1 = 'god like' AND key_part2 = 'legendary';
SELECT * FROM single_table WHERE key_part1 = 'god like' AND key_part2 = 'legendary' AND key_part3 = 'penta kill';
但是如果最左边的连续索引列并不全部是等值比较的话,它的访问方法就不能称为 ref 了,比方说这样:
SELECT * FROM single_table WHERE key_part1 = 'god like' AND key_part2 > 'legendary';
# ref_or_null
有时候我们不仅想找出某个二级索引列的值等于某个常数的记录,还想把该列的值为 NULL 的记录也找出来,就像下边这个查询:
mysql> explain SELECT * FROM single_table WHERE key1 = 'abc' OR key1 IS NULL;
+----+-------------+--------------+------------+-------------+---------------+----------+---------+-------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------------+------------+-------------+---------------+----------+---------+-------+------+----------+-----------------------+
| 1 | SIMPLE | single_table | NULL | ref_or_null | idx_key1 | idx_key1 | 303 | const | 3 | 100.00 | Using index condition |
+----+-------------+--------------+------------+-------------+---------------+----------+---------+-------+------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)
当使用二级索引而不是全表扫描的方式执行该查询时,这种类型的查询使用的访问方法就称为
ref_or_null

# range
我们之前介绍的几种访问方法都是在对索引列与某一个常数进行等值比较的时候才可能使用到( ref_or_null 比 较奇特,还计算了值为 NULL 的情况),但是有时候我们面对的搜索条件更复杂,比如下边这个查询:
mysql> explain SELECT * FROM single_table WHERE key2 IN (1438, 6328) OR (key2 >= 38 AND key2 <= 79);
+----+-------------+--------------+------------+-------+---------------+----------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------------+------------+-------+---------------+----------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | single_table | NULL | range | idx_key2 | idx_key2 | 5 | NULL | 3 | 100.00 | Using index condition |
+----+-------------+--------------+------------+-------+---------------+----------+---------+------+------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)
设计 MySQL 的大叔把这种利用索引进行范围匹配的访问方法称之为: range 。
 也就是从数学的角度看,每一个所谓的范围都是数轴上的一个 区间 ,3个范围也就对应着3个区间:
也就是从数学的角度看,每一个所谓的范围都是数轴上的一个 区间 ,3个范围也就对应着3个区间:
- 范围1: key2 = 1438
- 范围2: key2 = 6328
- 范围3: key2 ∈ [38, 79] ,注意这里是闭区间。
我们可以把那种索引列等值匹配的情况称之为 单点区间 ,上边所说的 范围1 和 范围2 都可以被称为单点区间, 像 范围3 这种的我们可以称为 连续范围区间。
# index
看下边这个查询:
mysql> explain SELECT key_part1, key_part2, key_part3 FROM single_table WHERE key_part2 = 'abc';
+----+-------------+--------------+------------+-------+---------------+--------------+---------+------+-------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------------+------------+-------+---------------+--------------+---------+------+-------+----------+--------------------------+
| 1 | SIMPLE | single_table | NULL | index | NULL | idx_key_part | 909 | NULL | 10625 | 10.00 | Using where; Using index |
+----+-------------+--------------+------------+-------+---------------+--------------+---------+------+-------+----------+--------------------------+
1 row in set, 1 warning (0.00 sec)
由于 key_part2 并不是联合索引 idx_key_part 最左索引列,所以我们无法使用 ref 或者 range 访问方法来执行这个语句。但是这个查询符合下边这两个条件:
- 它的查询列表只有3个列: key_part1 , key_part2 , key_part3 ,而索引 idx_key_part 又包含这三个列。
- 搜索条件中只有 key_part2 列。这个列也包含在索引 idx_key_part 中。
也就是说我们可以直接通过遍历 idx_key_part 索引的叶子节点的记录来比较 key_part2 = 'abc' 这个条件是否成立,把匹配成功的二级索引记录的 key_part1 , key_part2 , key_part3 列的值直接加到结果集中就行了。由 于二级索引记录比聚簇索记录小的多(聚簇索引记录要存储所有用户定义的列以及所谓的隐藏列,而二级索引记 录只需要存放索引列和主键),而且这个过程也不用进行回表操作,所以直接遍历二级索引比直接遍历聚簇索引的成本要小很多,设计 MySQL 的大叔就把这种采用遍历二级索引记录的执行方式称之为: index 。
# all
最直接的查询执行方式就是我们已经提了无数遍的全表扫描,对于 InnoDB 表来说也就是直接扫描聚簇索引,设 计 MySQL 的大叔把这种使用全表扫描执行查询的方式称之为: all 。
# 注意事项
# 重温 二级索引 + 回表
一般情况下只能利用单个二级索引执行查询,比方说下边的这个查询:
SELECT * FROM single_table WHERE key1 = 'abc' AND key2 > 1000;
查询优化器会识别到这个查询中的两个搜索条件:
- key1 = 'abc'
- key2 > 1000
优化器一般会根据 single_table 表的统计数据来判断到底使用哪个条件到对应的二级索引中查询扫描的行数会更少,选择那个扫描行数较少的条件到对应的二级索引中查询。然后将从该二级索引中查询到的结果经过回表得到完整的用户记录后再根据其余的 WHERE 条件过滤记录。 一般来说,等值查找比范围查找需要扫描的行数更少,所以这里假设优化器决定使用 idx_key1 索引进行查询,那么整个查询过程可以分为两个步骤:
- 步骤1:使用二级索引定位记录的阶段,也就是根据条件 key1 = 'abc' 从 idx_key1 索引代表的 B+ 树中找到对应的二级索引记录。
- 步骤2:回表阶段,也就是根据上一步骤中找到的记录的主键值进行 回表 操作,也就是到聚簇索引中找到对应的完整的用户记录,再根据条件 key2 > 1000 到完整的用户记录继续过滤。将最终符合过滤条件的记录返回给用户。
这里需要特别提醒大家的一点是,因为二级索引的节点中的记录只包含索引列和主键,所以在步骤1中使用 idx_key1 索引进行查询时只会用到与 key1 列有关的搜索条件,其余条件,比如 key2 > 1000 这个条件在步骤1中是用不到的,只有在步骤2完成回表操作后才能继续针对完整的用户记录中继续过滤。
# 明确range访问方法使用的范围区间
其实对于 B+ 树索引来说,只要索引列和常数使用 = 、 <=> 、 IN 、 NOT IN 、 IS NULL 、 IS NOT NULL 、> 、 < 、 >= 、 <= 、 BETWEEN 、 != (不等于也可以写成 <> )或者 LIKE 操作符连接起来,就可以产生一个所谓的 区间 。
小贴士:
LIKE操作符比较特殊,只有在匹配完整字符串或者匹配字符串前缀时才可以利用索引 IN操作符的效果和若干个等值匹配操作符=之间用OR连接起来是一样的,也就是说会产生多个单点区间,比如下边这两个语句的效果是一样的:
SELECT * FROM single_table WHERE key2 IN (1438, 6328);
SELECT * FROM single_table WHERE key2 = 1438 OR key2 = 6328;
# 简化搜索条件
比如下边这个查询:
SELECT * FROM single_table WHERE key2 > 100 AND common_field = 'abc';
请注意,这个查询语句中能利用的索引只有 idx_key2 一个,而 idx_key2 这个二级索引的记录中又不包含common_field 这个字段,所以在使用二级索引 idx_key2 定位记录的阶段用不到 common_field = 'abc' 这个条 件,这个条件是在回表获取了完整的用户记录后才使用的,而 范围区间 是为了到索引中取记录中提出的概念,所以在确定 范围区间 的时候不需要考虑 common_field = 'abc' 这个条件,我们在为某个索引确定范围区间的时 候只需要把用不到相关索引的搜索条件替换为 TRUE 就好了。
小贴士:
之所以把用不到索引的搜索条件替换为TRUE,是因为我们不打算使用这些条件进行在该索引上进行过滤,所以不管索引的记录满不满足这些条件,我们都把它们选取出来,待到之后回表的时候再使用它们过滤。
我们把上边的查询中用不到 idx_key2 的搜索条件替换后就是这样:
SELECT * FROM single_table WHERE key2 > 100 AND TRUE;
化简之后就是这样:
SELECT * FROM single_table WHERE key2 > 100;
也就是说最上边那个查询使用 idx_key2 的范围区间就是: (100, +∞) 。
再来看一下使用 OR 的情况:
SELECT * FROM single_table WHERE key2 > 100 OR common_field = 'abc';
同理,我们把使用不到 idx_key2 索引的搜索条件替换为 TRUE :
SELECT * FROM single_table WHERE key2 > 100 OR TRUE;
接着化简:
SELECT * FROM single_table WHERE TRUE;
这也就说说明如果我们强制使用 idx_key2 执行查询的话,对应的范围区间就是 (-∞, +∞) ,也就是需要将全部二级索引的记录进行回表,这个代价肯定比直接全表扫描都大了。也就是说一个使用到索引的搜索条件和没有使用该索引的搜索条件使用 OR 连接起来后是无法使用该索引的。
# 复杂搜索条件下找出范围匹配的区间
有的查询的搜索条件可能特别复杂,光是找出范围匹配的各个区间就挺烦的,比方说下边这个:
SELECT * FROM single_table WHERE
(key1 > 'xyz' AND key2 = 748 ) OR
(key1 < 'abc' AND key1 > 'lmn') OR
(key1 LIKE '%suf' AND key1 > 'zzz' AND (key2 < 8000 OR common_field = 'abc')) ;
- 首先查看 WHERE 子句中的搜索条件都涉及到了哪些列,哪些列可能使用到索引。
这个查询的搜索条件涉及到了 key1 、 key2 、 common_field 这3个列,然后 key1 列有普通的二级索引 idx_key1 , key2 列有唯一二级索引 idx_key2 。
- 对于那些可能用到的索引,分析它们的范围区间。
- 假设我们使用 idx_key1 执行查询
我们需要把那些用不到该索引的搜索条件暂时移除掉,移除方法也简单,直接把它们替换为 TRUE 就好了。上边的查询中除了有关 key2 和 common_field 列不能使用到 idx_key1 索引外, key1 LIKE '%suf' 也使用不到索引,所以把这些搜索条件替换为 TRUE 之后的样子就是这样:
(key1 > 'xyz' AND TRUE ) OR
(key1 < 'abc' AND key1 > 'lmn') OR
(TRUE AND key1 > 'zzz' AND (TRUE OR TRUE))
# 化简
(key1 > 'xyz') OR
(key1 < 'abc' AND key1 > 'lmn') OR
(key1 > 'zzz')
# 替换掉永远为 TRUE 或 FALSE 的条件
# 因为符合 key1 < 'abc' AND key1 > 'lmn' 永远为 FALSE ,所以上边的搜索条件可以被写成这样:
(key1 > 'xyz') OR (key1 > 'zzz')
继续化简区间
key1 > 'xyz' 和 key1 > 'zzz' 之间使用 OR 操作符连接起来的,意味着要取并集,所以最终的结 果化简的到的区间就是: key1 > xyz 。也就是说:上边那个有一坨搜索条件的查询语句如果使用 idx_key1 索引执行查询的话,需要把满足 key1 > xyz 的二级索引记录都取出来,然后拿着这些记 录的id再进行回表,得到完整的用户记录之后再使用其他的搜索条件进行过滤。
mysql> explain SELECT * FROM single_table WHERE
-> (key1 > 'xyz' AND key2 = 748 ) OR
-> (key1 < 'abc' AND key1 > 'lmn') OR
-> (key1 LIKE '%suf' AND key1 > 'zzz' AND (key2 < 8000 OR common_field = 'abc')) ;
+----+-------------+--------------+------------+-------+-------------------+----------+---------+------+------+----------+------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------------+------------+-------+-------------------+----------+---------+------+------+----------+------------------------------------+
| 1 | SIMPLE | single_table | NULL | range | idx_key2,idx_key1 | idx_key1 | 303 | NULL | 1 | 100.00 | Using index condition; Using where |
+----+-------------+--------------+------------+-------+-------------------+----------+---------+------+------+----------+------------------------------------+
1 row in set, 1 warning (0.01 sec)
- 假设我们使用 idx_key2 执行查询
我们需要把那些用不到该索引的搜索条件暂时使用 TRUE 条件替换掉,其中有关 key1 和 common_field 的搜索条件都需要被替换掉,替换结果就是:
(TRUE AND key2 = 748 ) OR
(TRUE AND TRUE) OR
(TRUE AND TRUE AND (key2 < 8000 OR TRUE))
# key2 < 8000 OR TRUE 的结果肯定是 TRUE 呀,也就是说化简之后的搜索条件成这样了:
key2 = 748 OR TRUE
# 这个化简之后的结果就更简单了:
TRUE
这个结果也就意味着如果我们要使用 idx_key2 索引执行查询语句的话,需要扫描 idx_key2 二级索引的所有记录,然后再回表,这不是得不偿失么,所以这种情况下不会使用 idx_key2 索引的
# 索引合并
我们前边说过 MySQL 在一般情况下执行一个查询时最多只会用到单个二级索引,但不是还有特殊情况么,在这些 特殊情况下也可能在一个查询中使用到多个二级索引,设计 MySQL 的大叔把这种使用到多个索引来完成一次查询 的执行方法称之为: index merge ,具体的索引合并算法有下边三种。 https://dev.mysql.com/doc/refman/5.7/en/index-merge-optimization.html (opens new window)
**Intersection合并 **
Intersection 翻译过来的意思是 交集 。这里是说某个查询可以使用多个二级索引,将从多个二级索引中查询到的结果取交集,比方说下边这个查询:
SELECT * FROM single_table WHERE key1 = 'a' AND key3 = 'b';
假设这个查询使用 Intersection 合并的方式执行的话,那这个过程就是这样的:
- 从 idx_key1 二级索引对应的 B+ 树中取出 key1 = 'a' 的相关记录。
- 从 idx_key3 二级索引对应的 B+ 树中取出 key3 = 'b' 的相关记录。
- 二级索引的记录都是由 索引列 + 主键 构成的,所以我们可以计算出这两个结果集中 id 值的交集。
- 按照上一步生成的 id 值列表进行回表操作,也就是从聚簇索引中把指定 id 值的完整用户记录取出来,返回 给用户。
二级索引必须等值查询,联合索引必须所有部分都等值进行匹配 聚簇索引可以范围查找
**Union合并 **
我们在写查询语句时经常想把既符合某个搜索条件的记录取出来,也把符合另外的某个搜索条件的记录取出来, 我们说这些不同的搜索条件之间是 OR 关系。
SELECT * FROM single_table WHERE key1 = 'a' OR key3 = 'b'
- 情况一:二级索引列是等值匹配的情况,对于联合索引来说,在联合索引中的每个列都必须等值匹配,不能出现只出现匹配部分列的情况。
- 情况二:主键列可以是范围匹配
- 情况三:使用 Intersection 索引合并的搜索条件
Sort-Union合并
该访问算法适用于WHERE子句转换为多个OR组合的范围条件,但不适用Index Merge union算法。
SELECT * FROM single_table WHERE key1 < 'a' OR key3 > 'z'
- 先根据 key1 < 'a' 条件从 idx_key1 二级索引总获取记录,并按照记录的主键值进行排序
- 再根据 key3 > 'z' 条件从 idx_key3 二级索引总获取记录,并按照记录的主键值进行排序
- 因为上述的两个二级索引主键值都是排好序的,剩下的操作和 Union 索引合并方式就一样了。
Sort-Union排序联合算法和Union联合算法之间的区别在于Sort-Union排序联合算法必须首先获取所有行的 ID 并在返回任何行之前对它们进行排序。
# 多表连接的原理
准备工作
mysql> create table t1(m1 int, n1 char(1));
Query OK, 0 rows affected (2.11 sec)
mysql> create table t2(m2 int, n2 char(1));
Query OK, 0 rows affected (0.45 sec)
mysql> insert into t1 values(1,'a'),(2,'b'),(3,'c');
Query OK, 3 rows affected (0.21 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> insert into t2 values(2,'b'),(3,'c'),(4,'d');
Query OK, 3 rows affected (0.13 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> select * from t1;
+------+------+
| m1 | n1 |
+------+------+
| 1 | a |
| 2 | b |
| 3 | c |
+------+------+
3 rows in set (0.02 sec)
mysql> select * from t2;
+------+------+
| m2 | n2 |
+------+------+
| 2 | b |
| 3 | c |
| 4 | d |
+------+------+
连接 的本质就是把各个连接表中的记录都取出来依次匹配的组合加入结果集并返回给用户。所以我们把 t1 和 t2 两个表连接起来的过程如下图所示:
 这个过程看起来就是把 t1 表的记录和 t2 的记录连起来组成新的更大的记录,所以这个查询过程称之为连接查询。连接查询的结果集中包含一个表中的每一条记录与另一个表中的每一条记录相互匹配的组合,像这样的结果 集就可以称之为 笛卡尔积 。因为表 t1 中有3条记录,表 t2 中也有3条记录,所以这两个表连接之后的笛卡尔积 就有 3×3=9 行记录。在 MySQL 中,连接查询的语法也很随意,只要在 FROM 语句后边跟多个表名就好了,比如 我们把 t1 表和 t2 表连接起来的查询语句可以写成这样:
这个过程看起来就是把 t1 表的记录和 t2 的记录连起来组成新的更大的记录,所以这个查询过程称之为连接查询。连接查询的结果集中包含一个表中的每一条记录与另一个表中的每一条记录相互匹配的组合,像这样的结果 集就可以称之为 笛卡尔积 。因为表 t1 中有3条记录,表 t2 中也有3条记录,所以这两个表连接之后的笛卡尔积 就有 3×3=9 行记录。在 MySQL 中,连接查询的语法也很随意,只要在 FROM 语句后边跟多个表名就好了,比如 我们把 t1 表和 t2 表连接起来的查询语句可以写成这样:
mysql> select * from t1,t2;
+------+------+------+------+
| m1 | n1 | m2 | n2 |
+------+------+------+------+
| 1 | a | 2 | b |
| 2 | b | 2 | b |
| 3 | c | 2 | b |
| 1 | a | 3 | c |
| 2 | b | 3 | c |
| 3 | c | 3 | c |
| 1 | a | 4 | d |
| 2 | b | 4 | d |
| 3 | c | 4 | d |
+------+------+------+------+
9 rows in set (0.03 sec)
# 连接过程简介
比方说3个100行记录的表连接起来产生的 笛卡尔积 就有 100×100×100=1000000 行数 据!所以在连接的时候过滤掉特定记录组合是有必要的,在连接查询中的过滤条件可以分成两种:
- 涉及单表的条件
这种只设计单表的过滤条件我们之前都提到过一万遍了,我们之前也一直称为 搜索条件 ,比如 t1.m1 > 1 是只针对 t1 表的过滤条件, t2.n2 < 'd' 是只针对 t2 表的过滤条件。
- 涉及两表的条件
这种过滤条件我们之前没见过,比如 t1.m1 = t2.m2 、 t1.n1 > t2.n2 等,这些条件中涉及到了两个表,我 们稍后会仔细分析这种过滤条件是如何使用的哈。
下边我们就要看一下携带过滤条件的连接查询的大致执行过程了,比方说下边这个查询语句:
SELECT * FROM t1, t2 WHERE t1.m1 > 1 AND t1.m1 = t2.m2 AND t2.n2 < 'd';
在这个查询中我们指明了这三个过滤条件:
- t1.m1 > 1
- t1.m1 = t2.m2
- t2.n2 < 'd'
那么这个连接查询的大致执行过程如下:
- 首先确定第一个需要查询的表,这个表称之为 驱动表 。怎样在单表中执行查询语句我们在前一章都唠叨过了,只需要选取代价最小的那种访问方法去执行单表查询语句就好了(就是说从const、ref、ref_or_null、 range、index、all这些执行方法中选取代价最小的去执行查询)。此处假设使用 t1 作为驱动表,那么就需 要到 t1 表中找满足 t1.m1 > 1 的记录,因为表中的数据太少,我们也没在表上建立二级索引,所以此处查 询 t1 表的访问方法就设定为 all 吧,也就是采用全表扫描的方式执行单表查询。所以查询过程就如下图所示:
 我们可以看到, t1 表中符合 t1.m1 > 1 的记录有两条。
我们可以看到, t1 表中符合 t1.m1 > 1 的记录有两条。 - 针对上一步骤中从驱动表产生的结果集中的每一条记录,分别需要到 t2 表中查找匹配的记录,所谓匹配的记录 ,指的是符合过滤条件的记录。因为是根据 t1 表中的记录去找 t2 表中的记录,所以 t2 表也可以被称之为 被驱动表 。上一步骤从驱动表中得到了2条记录,所以需要查询2次 t2 表。此时涉及两个表的列的 过滤条件 t1.m1 = t2.m2 就派上用场了:
当 t1.m1 = 2 时,过滤条件 t1.m1 = t2.m2 就相当于 t2.m2 = 2 ,所以此时 t2 表相当于有了 t2.m2 = 2 、 t2.n2 < 'd' 这两个过滤条件,然后到 t2 表中执行单表查询。
当 t1.m1 = 3 时,过滤条件 t1.m1 = t2.m2 就相当于 t2.m2 = 3 ,所以此时 t2 表相当于有了 t2.m2 = 3 、 t2.n2 < 'd' 这两个过滤条件,然后到 t2 表中执行单表查询。
所以整个连接查询的执行过程就如下图所示:

也就是说整个连接查询最后的结果只有两条符合过滤条件的记录
mysql> SELECT * FROM t1, t2 WHERE t1.m1 > 1 AND t1.m1 = t2.m2 AND t2.n2 < 'd';
+------+------+------+------+
| m1 | n1 | m2 | n2 |
+------+------+------+------+
| 2 | b | 2 | b |
| 3 | c | 3 | c |
+------+------+------+------+
2 rows in set (0.00 sec)
从上边两个步骤可以看出来,我们上边唠叨的这个两表连接查询共需要查询1次 t1 表,2次 t2 表。当然这是在特定的过滤条件下的结果,如果我们把 t1.m1 > 1 这个条件去掉,那么从 t1 表中查出的记录就有3条,就需要 查询3次 t2 表了。也就是说在两表连接查询中,驱动表只需要访问一次,被驱动表可能被访问多次。
# 内连接和外连接
连接中的过滤条件
- WHERE 子句中的过滤条件
WHERE 子句中的过滤条件就是我们平时见的那种,不论是内连接还是外连接,凡是不符合 WHERE 子句中的过滤条件的记录都不会被加入最后的结果集。
- ON 子句中的过滤条件
对于外连接的驱动表的记录来说,如果无法在被驱动表中找到匹配 ON 子句中的过滤条件的记录,那么该记录仍然会被加入到结果集中,对应的被驱动表记录的各个字段使用 NULL 值填充。 需要注意的是,这个 ON 子句是专门为外连接驱动表中的记录在被驱动表找不到匹配记录时应不应该把该记录加入结果集这个场景下提出的,所以如果把 ON 子句放到内连接中, MySQL 会把它和 WHERE 子句一样对 待,也就是说:内连接中的WHERE子句和ON子句是等价的。
一般情况下,我们都把只涉及单表的过滤条件放到 WHERE 子句中,把涉及两表的过滤条件都放到 ON 子句中,我们也一般把放到 ON 子句中的过滤条件也称之为 连接条件 。
# 嵌套循环连接
Nested-Loop Join 对于两表连接来说,驱动表只会被访问一遍,但被驱动表却要被访问到好多遍,具体访问几遍取决于对驱动表执行单表查询后的结果集中的记录条数。对于内连接来说,选取哪个表为驱动表都没关系,而外连接的驱动表是固定的,也就是说左(外)连接的驱动表就是左边的那个表,右(外)连接的驱动表就是右边的那个表
- 步骤1:选取驱动表,使用与驱动表相关的过滤条件,选取代价最低的单表访问方法来执行对驱动表的单表查询。
- 步骤2:对上一步骤中查询驱动表得到的结果集中每一条记录,都分别到被驱动表中查找匹配的记录。
 如果有3个表进行连接的话,那么 步骤2 中得到的结果集就像是新的驱动表,然后第三个表就成为了被驱动表, 重复上边过程,也就是 步骤2 中得到的结果集中的每一条记录都需要到 t3 表中找一找有没有匹配的记录,用伪 代码表示一下这个过程就是这样:
如果有3个表进行连接的话,那么 步骤2 中得到的结果集就像是新的驱动表,然后第三个表就成为了被驱动表, 重复上边过程,也就是 步骤2 中得到的结果集中的每一条记录都需要到 t3 表中找一找有没有匹配的记录,用伪 代码表示一下这个过程就是这样:
for each row in t1 { #此处表示遍历满足对t1单表查询结果集中的每一条记录
for each row in t2 { #此处表示对于某条t1表的记录来说,遍历满足对t2单表查询结果集中的 每一条记录
for each row in t3 { #此处表示对于某条t1和t2表的记录组合来说,对t3表进行单表查询
if row satisfies join conditions, send to client
}
}
}
这个过程就像是一个嵌套的循环,所以这种驱动表只访问一次,但被驱动表却可能被多次访问,访问次数取决于对驱动表执行单表查询后的结果集中的记录条数的连接执行方式称之为 嵌套循环连接 ( Nested-Loop Join ), 这是最简单,也是最笨拙的一种连接查询算法。
建立了索引不一定使用索引,只有在 二级索引 + 回表 的代价比全表扫描的代价更低时才会使用索引。 另外,有时候连接查询的查询列表和过滤条件中可能只涉及被驱动表的部分列,而这些列都是某个索引的一部 分,这种情况下即使不能使用 eq_ref 、 ref 、 ref_or_null 或者 range 这些访问方法执行对被驱动表的查询的 话,也可以使用索引扫描,也就是 index 的访问方法来查询被驱动表。所以我们建议在真实工作中最好不要使用 * 作为查询列表,最好把真实用到的列作为查询列表。
尽量减少访问被驱动表的次数
join buffer就是执行连接查询前申请的一块固定大小的内存,先把若干条驱动表结果集中的记录装在这个 join buffer 中,然后开始扫描被驱动表,每一条被驱动表的记录一次性和 join buffer 中的多条驱动表记录做匹配,因为匹配的过程都是在内存中完成的,所以这样可以显著减少被驱动表的 I/O 代价。
 最好的情况是 join buffer 足够大,能容纳驱动表结果集中的所有记录,这样只需要访问一次被驱动表就可以完 成连接操作了。设计 MySQL 的大叔把这种加入了 join buffer 的嵌套循环连接算法称之为 基于块的嵌套连接 (Block Nested-Loop Join)算法
最好的情况是 join buffer 足够大,能容纳驱动表结果集中的所有记录,这样只需要访问一次被驱动表就可以完 成连接操作了。设计 MySQL 的大叔把这种加入了 join buffer 的嵌套循环连接算法称之为 基于块的嵌套连接 (Block Nested-Loop Join)算法
可以通过启动参数或者系统变量 join_buffer_size 进行配置,默认大小 256KB,最小可以设置为 128byte
驱动表的记录并不是所有列都会被放到 join buffer 中,只有查询列表中的列和过滤条件中的列才会被放到 join buffer 中,所以再次提醒我们,最好不要把 * 作为查询列表,只需要把我们关心的列放到 查询列表就好了,这样还可以在 join buffer 中放置更多的记录
# 基于成本的优化
在 MySQL 中一条查询语句的执行成本是由 下边这两个方面组成的:
- I/O 成本
我们的表经常使用的 MyISAM 、 InnoDB 存储引擎都是将数据和索引都存储到磁盘上的,当我们想查询表中的记录时,需要先把数据或者索引加载到内存中然后再操作。这个从磁盘到内存这个加载的过程损耗的时间称 之为 I/O 成本。
- CPU 成本
读取以及检测记录是否满足对应的搜索条件、对结果集进行排序等这些操作损耗的时间称之为 CPU 成本。
对于 InnoDB 存储引擎来说,页是磁盘和内存之间交互的基本单位,设计 MySQL 的大叔规定读取一个页面花费的成本默认是 1.0 ,读取以及检测一条记录是否符合搜索条件的成本默认是 0.2 。 1.0 、 0.2 这些数字称之为 成本常数。不管读取记录时需不需要检测是否满足搜索条件,其成本都算是0.2。
在一条单表查询语句真正执行之前, MySQL 的查询优化器会找出执行该语句所有可能使用的方案,对比之后找出 成本最低的方案,这个成本最低的方案就是所谓的 执行计划
- 根据搜索条件,找出所有可能使用的索引
- 计算全表扫描的代价
- 计算使用不同索引执行查询的代价
- 对比各种执行方案的代价,找出成本最低的那一个
准备工作
CREATE TABLE single_table (
id INT NOT NULL AUTO_INCREMENT,
key1 VARCHAR(100),
key2 INT,
key3 VARCHAR(100),
key_part1 VARCHAR(100),
key_part2 VARCHAR(100),
key_part3 VARCHAR(100),
common_field VARCHAR(100),
PRIMARY KEY (id),
KEY idx_key1 (key1),
UNIQUE KEY idx_key2 (key2),
KEY idx_key3 (key3),
KEY idx_key_part(key_part1, key_part2, key_part3)
) Engine=InnoDB CHARSET=utf8;
还是假设这个表里边儿有10000条记录,除 id 列外其余的列都插入随机值
SELECT * FROM single_table WHERE
key1 IN ('a', 'b', 'c') AND
key2 > 10 AND key2 < 1000 AND
key3 > key2 AND
key_part1 LIKE '%hello%' AND
common_field = '123';
我们分析一下上边查询中涉及到的几个搜索条件:
- key1 IN ('a', 'b', 'c') ,这个搜索条件可以使用二级索引 idx_key1 。
- key2 > 10 AND key2 < 1000 ,这个搜索条件可以使用二级索引 idx_key2 。
- key3 > key2 ,这个搜索条件的索引列由于没有和常数比较,所以并不能使用到索引。
- key_part1 LIKE '%hello%' , key_part1 通过 LIKE 操作符和以通配符开头的字符串做比较,不可以适用
索引。
- common_field = '123' ,由于该列上压根儿没有索引,所以不会用到索引。
综上所述,上边的查询语句可能用到的索引,也就是 possible keys 只有 idx_key1 和 idx_key2 。
# 计算全表扫描的代价
计算表中所有的页+所有的记录数
查看表统计信息
mysql> SHOW TABLE STATUS LIKE 'single_table'\G
*************************** 1. row ***************************
Name: single_table
Engine: InnoDB
Version: 10
Row_format: Dynamic
Rows: 9693
Avg_row_length: 163
Data_length: 1589248
Max_data_length: 0
Index_length: 2752512
Data_free: 4194304
Auto_increment: 10001
Create_time: 2018-12-10 13:37:23
Update_time: 2018-12-10 13:38:03
Check_time: NULL
Collation: utf8_general_ci
Checksum: NULL
Create_options:
Comment:
1 row in set (0.01 sec)
- Rows
表中记录数。在 MyISAM 下是准确的,InnoDB 下是一个估计值
- Data_length
表占用的存储空间字节数。MyISAM 下是数据文件的大小,InnoDB 下相当于聚簇索引占用的存储空间大小,即: Data_length = 聚簇索引的页面数量 * 每个页面大小 每个页默认16kb,倒推: 聚簇索引的页面数量 = 1589248 / 16k / 1024 = 97
计算成本还要微调一下,MySQL固定值
- I/O 成本
97 * 1.0 + 1.1 = 98.1
97:聚簇索引占用页数
1.0:加载一个页面的成本常数
1.1:微调值,固定值
CPU 成本
9693 * 0.2 + 1.0 = 1939.6- 9693:统计数据表的记录数,InnoDB是估计值
- 0.2:访问一条记录所需的成本常数
- 1.0:微调值,固定值
总成本
98.1 + 1939.6 = 2037.7
# 索引执行查询的代价
MySQL 查询优化器先分析使用唯一二级索引的成本,再分析使用普通索引的成本
使用idx_key2执行查询的成本分析 idx_key2 对应的搜索条件是: key2 > 10 AND key2 < 1000 ,也就是说对应的范围区间就是: (10, 1000)
对于使用 二级索引 + 回表 方式的查询,设计 MySQL 的大叔计算这种查询的成本依赖两个方面的数据:
- 范围区间的数量
不论范围区间的二级索引占用了多少页面,查询优化器固定认为读取索引的一个范围区间的I/O成本和读取一个页面是相同的。本例中使用 idx_key2 的范围区间只有一个: (10, 1000),即: 1 * 1.0 = 1.0
- 需要回表的记录数
优化器需要计算二级索引的某个范围区间到底包含多少条记录,对于本例来说就是要计算 idx_key2 在 (10, 1000) 这个范围区间中包含多少二级索引记录,计算过程是这样的:
- 步骤1:先根据 key2 > 10 这个条件访问一下 idx_key2 对应的 B+ 树索引,找到满足 key2 > 10 这个条件的第一条记录,我们把这条记录称之为 区间最左记录 。我们前头说过在 B+ 数树中定位一条记录的过 程是贼快的,是常数级别的,所以这个过程的性能消耗是可以忽略不计的。
- 步骤2:然后再根据 key2 < 1000 这个条件继续从 idx_key2 对应的 B+ 树索引中找出第一条满足这个条件的记录,我们把这条记录称之为 区间最右记录 ,这个过程的性能消耗也可以忽略不计的。
- 步骤3:如果 区间最左记录 和 区间最右记录 相隔不太远(在 MySQL 5.7.21 这个版本里,只要相 隔不大于10个页面即可),那就可以精确统计出满足 key2 > 10 AND key2 < 1000 条件的二级索引 记录条数。否则只沿着 区间最左记录 向右读10个页面,计算平均每个页面中包含多少记录,然后 用这个平均值乘以 区间最左记录 和 区间最右记录之间的页面数量就可以了。那么问题又来了,怎 么估计 区间最左记录 和 区间最右记录之间有多少个页面呢?计算它们父节点(非叶子节点)中对应的目录项记录之间隔着几条记录

假设这个范围内的记录数有95条,读取这 95 条二级索引记录需要付出的 CPU 成本 就是: 95 * 0.2 + 0.01 = 19.01
- 95:二级索引记录条数
- 0.2:读取一条记录成本常数
- 0.01:微调值,固定值
通过二级索引获取到记录之后,还需要干两件事儿:
- 根据这些记录里的主键值到聚簇索引中做回表操作,作者认为每次回表操作都相当于访问一个页面,也就是说二级索引范围区间有多少记录,就需要进行多少次回表操作,也就是需要进行多少次页面 I/O 。我们上边统计了使用 idx_key2 二级索引执行查询时,预计有 95 条二级索引记录需要进行回表操作,所以回表操作带来 的 I/O 成本就是:
95 * 1.0 = 95.0
- 95:二级索引记录数
- 1.0:一个页面 I/O 的成本常熟
- 回表操作后得到的完整用户记录,然后再检测其他搜索条件是否成立 回表操作的本质就是通过二级索引记录的主键值到聚簇索引中找到完整的用户记录,然后再检测除 key2 > 10 AND key2 < 1000 这个搜索条件以外的搜索条件是否成立。因为我们通过范围区间获取 到二级索引记录共 95 条,也就对应着聚簇索引中 95 条完整的用户记录,读取并检测这些完整的用户记录是否符合其余的搜索条件的 CPU 成本如下:
95 * 0.2 = 19.0
- 95:待检测记录的条数
- 0.2:检查一条记录是否符合给定的搜索条件的成本常数
所以本例中使用 idx_key2 执行查询的成本就如下所示:
- I/O 成本:
1.0 + 95 * 1.0 = 96.0 二级索引范围区间数量 + 二级索引记录(回表次数)
- CPU 成本:
95 * 0.2 + 0.01 + 95 * 0.2 = 38.01 读取二级索引记录 + 回表后读取聚簇索引的记录 综上所述,使用 idx_key2 执行查询的总成本就是: 96.0 + 38.01 = 134.01
使用idx_key1执行查询的成本分析 idx_key1 对应的搜索条件是: key1 IN ('a', 'b', 'c') ,也就是说相当于3个单点区间:
- ['a', 'a']
- ['b', 'b']
- ['c', 'c']
与使用idx_key2的情况类似,我们也需要计算使用idx_key1时需要访问的范围区间数量以及需要回表的记录数:
范围区间数量 使用idx_key1执行查询时很显然有3个单点区间,所以访问这3个范围区间的二级索引付出的I/O成本就是:
3 * 1.0 = 3.0
需要回表的记录数 由于使用idx_key1时有3个单点区间,所以每个单点区间都需要查找一遍对应的二级索引记录数:
- 查找单点区间 ['a', 'a'] 对应的二级索引记录数
计算单点区间对应的二级索引记录数和计算连续范围区间对应的二级索引记录数是一样的,都是先计算区间最左记录和区间最右记录,然后再计算它们之间的记录数,具体算法上边都唠叨过了,就不赘述了。最后计算得到单点区间['a', 'a']对应的二级索引记录数是:35。
- 查找单点区间['b', 'b']对应的二级索引记录数
与上同理,计算得到本单点区间对应的记录数是:44。
- 查找单点区间['c', 'c']对应的二级索引记录数
与上同理,计算得到本单点区间对应的记录数是:39。 所以,这三个单点区间总共需要回表的记录数就是: 35 + 44 + 39 = 118
- 读取这些二级索引记录的CPU成本就是:
118 * 0.2 + 0.01 = 23.61
- 根据这些记录里的主键值到聚簇索引中做回表操作所需的I/O成本就是:
118 * 1.0 = 118.0
- 回表操作后得到的完整用户记录,然后再比较其他搜索条件是否成立此步骤对应的CPU成本就是:
118 * 0.2 = 23.6
所以本例中使用 idx_key1 执行查询的成本就如下所示:
- I/O成本:
3.0 + 118 * 1.0 = 121.0 (范围区间的数量 + 预估的二级索引记录条数)
- CPU成本:
118 * 0.2 + 0.01 + 118 x 0.2 = 47.21 (读取二级索引记录的成本 + 读取并检测回表后聚簇 索引记录的成本) 综上所述,使用idx_key1执行查询的总成本就是: 121.0 + 47.21 = 168.21
**是否有可能使用索引合并(Index Merge) ** 本例中有关 key1 和 key2 的搜索条件是使用 AND 连接起来的,而对于 idx_key1 和 idx_key2 都是范围查询,也就是说查找到的二级索引记录并不是按照主键值进行排序的,并不满足使用 Intersection 索引合并的条件,所以并不会使用索引合并。
- 全表扫描的成本: 2037.7
- 使用 idx_key2 的成本: 134.01
- 使用 idx_key1 的成本: 168.21
很显然,使用 idx_key2 的成本最低,所以当然选择 idx_key2 来执行查询
# 索引统计数据的成本
有时候使用索引执行查询时会有许多单点区间,比如使用 IN 语句就很容易产生非常多的单点区间,比如下边这个查询(下边查询语句中的 ... 表示还有很多参数):
SELECT * FROM single_table WHERE key1 IN ('aa1', 'aa2', 'aa3', ... , 'zzz');
很显然,这个查询可能使用到的索引就是 idx_key1 ,由于这个索引并不是唯一二级索引,所以并不能确定一个单点区间对应的二级索引记录的条数有多少,需要我们去计算。计算方式我们上边已经介绍过了,就是先获取索引对应的 B+ 树的 区间最左记录 和 区间最右记录 ,然后再计算这两条记录之间有多少记录(记录条数少的时候可以做到精确计算,多的时候只能估算)。设计 MySQL 的大叔把这种通过直接访问索引对应的 B+ 树来计算某个范围区间对应的索引记录条数的方式称之为 index dive 。
当 index dive 次数太多时(in的参数),对性能也有影响,所以可以进行数量限制
系统变量 eq_range_index_dive_limit ,我们看一下在 MySQL 5.7.21 中这个系统变量的默认值:
mysql> SHOW VARIABLES LIKE '%dive%';
+---------------------------+-------+
| Variable_name | Value |
+---------------------------+-------+
| eq_range_index_dive_limit | 200 |
+---------------------------+-------+
1 row in set (0.08 sec)
也就是说如果我们的 IN 语句中的参数个数小于200个的话,将使用 index dive 的方式计算各个单点区间对应的记录条数,如果大于或等于200个的话,可就不能使用 index dive 了
查看某个表中索引的统计数据可以使用 SHOW INDEX FROM 表名 的语法
mysql> SHOW INDEX FROM single_table;
+--------------+------------+--------------+--------------+-------------+-----------+-----
--------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Card
inality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+--------------+------------+--------------+--------------+-------------+-----------+-----
--------+----------+--------+------+------------+---------+---------------+
| single_table | 0 | PRIMARY | 1 | id | A |
9693 | NULL | NULL | | BTREE | | |
| single_table | 0 | idx_key2 | 1 | key2 | A |
9693 | NULL | NULL | YES | BTREE | | |
| single_table | 1 | idx_key1 | 1 | key1 | A |
968 | NULL | NULL | YES | BTREE | | |
| single_table | 1 | idx_key3 | 1 | key3 | A |
799 | NULL | NULL | YES | BTREE | | |
| single_table | 1 | idx_key_part | 1 | key_part1 | A |
9673 | NULL | NULL | YES | BTREE | | |
| single_table | 1 | idx_key_part | 2 | key_part2 | A |
9999 | NULL | NULL | YES | BTREE | | |
| single_table | 1 | idx_key_part | 3 | key_part3 | A |
10000 | NULL | NULL | YES | BTREE | | |
+--------------+------------+--------------+--------------+-------------+-----------+-----
--------+----------+--------+------+------------+---------+---------------+
7 rows in set (0.01 sec)
| 属性名 | 描述 |
|---|---|
| Table | 索引所属表的名称。 |
| Non_unique | 索引列的值是否是唯一的,聚簇索引和唯一二级索引的该列值为 0 ,普通二级索引该列值为 1 。 |
| Key_name | 索引的名称。 |
| Seq_in_index | 索引列在索引中的位置,从1开始计数。比如对于联合索引 idx_key_part ,来说, key_part1 、 key_part2和 key_part3 对应的位置分别是1、2、3。 |
| Column_name | 索引列的名称。 |
| Collation | 索引列中的值是按照何种排序方式存放的,值为 A 时代表升序存放,为 NULL 时代表降序存放。 |
| Cardinality | 索引列中不重复值的数量。后边我们会重点看这个属性的。 |
| Sub_part | 对于存储字符串或者字节串的列来说,有时候我们只想对这些串的前 n 个字符或字节建立索引,这个属性表示的就是那个 n 值。如果对完整的列建立索引的话,该属性的值就是 NULL 。 |
| Packed | 索引列如何被压缩, NULL 值表示未被压缩。这个属性我们暂时不了解,可以先忽略掉。 |
| Null | 该索引列是否允许存储 NULL 值。 |
| Index_type | 使用索引的类型,我们最常见的就是 BTREE ,其实也就是 B+ 树索引。 |
| Comment | 索引列注释信息。 |
| Index_comment | 索引注释信息。 |
实我们现在最在意的是 Cardinality 属性, Cardinality 直译过来就是 基数 的意思,表示索引列中不重复值的个数。对于InnoDB存储引擎来说,使用SHOW INDEX语句展示出来的某个索引列的Cardinality属性是一个估计值,并不是精确的。
当 IN 语句中的参数个数大于或等于系统变量 eq_range_index_dive_limit 的值的话,就不会使用
index dive 的方式计算各个单点区间对应的索引记录条数,而是使用索引统计数据,这里所指的 索引统计数据 指的是这两个值:
- 使用 SHOW TABLE STATUS 展示出的 Rows 值,也就是一个表中有多少条记录。
- 使用 SHOW INDEX 语句展示出的 Cardinality 属性。
结合上一个 Rows 统计数据,我们可以针对索引列,计算出平均一个值重复多少次。 一个值的重复次数 ≈ Rows ÷ Cardinality
以 single_table 表的 idx_key1 索引为例,它的 Rows 值是 9693 ,它对应索引列 key1 的 Cardinality 值是
968 ,所以我们可以计算 key1 列平均单个值的重复次数就是:
9693 ÷ 968 ≈ 10(条)
此时再看上边那条查询语句:
SELECT * FROM single_table WHERE key1 IN ('aa1', 'aa2', 'aa3', ... , 'zzz');
假设 IN 语句中有20000个参数的话,就直接使用统计数据来估算这些参数需要单点区间对应的记录条数了,每个参数大约对应 10 条记录,所以总共需要回表的记录数就是:
20000 x 10 = 200000
使用统计数据来计算单点区间对应的索引记录条数可比 index dive 的方式简单多了,但是它的致命弱点就是: 不精确!。使用统计数据算出来的查询成本与实际所需的成本可能相差非常大。
小贴士: 大家需要注意一下,在MySQL 5.7.3以及之前的版本中,
eq_range_index_dive_limit的默认值为10,之后的版本默认值为200。所以如果大家采用的是5.7.3以及之前的版本的话,很容易采用索引统计数据而不是index dive的方式来计算查询成本。当你的查询中使用到了IN查询,但是却实际没有用到索引,就应该考虑一下是不是由于eq_range_index_dive_limit值太小导致的。
# condition filtering
我们把对驱动表进行查询后得到的记录条数称之为驱动表的 扇出 (英文名: fanout )。很显然驱动表的扇出值越小,对被驱动表的查询次数也就越少,连接查询的总成本也就越低。当查询优化器想计算整个连接查询所使用的成本时,就需要计算出驱动表的扇出值,有的时候扇出值的计算是很容易的,有时候就靠 _**猜 **_了,这个 **_猜 _**的过程称之为 condition filtering
# 两表连接的成本分析
连接查询的成本计算公式是这样的: 连接查询总成本 = 单次访问驱动表的成本 + 驱动表扇出数 x 单次访问被驱动表的成本
对于左(外)连接和右(外)连接查询来说,它们的驱动表是固定的,所以想要得到最优的查询方案只需要:
- 分别为驱动表和被驱动表选择成本最低的访问方法。
可是对于内连接来说,驱动表和被驱动表的位置是可以互换的,所以需要考虑两个方面的问题:
- 不同的表作为驱动表最终的查询成本可能是不同的,也就是需要考虑最优的表连接顺序。
- 然后分别为驱动表和被驱动表选择成本最低的访问方法。
连接查询成本占大头的其实是 驱动表扇出数 x 单次访问被驱动表的成本 ,所以我们的优化 重点其实是下边这两个部分:
- 尽量减少驱动表的扇出
- 对被驱动表的访问成本尽量低这一点对于我们实际书写连接查询语句时十分有用,我们需要尽量在被驱动表的连接列上建立索引,这样就可以使用 ref 访问方法来降低访问被驱动表的成本了。如果可以,被驱动表的连接列最好是该表的主键或者唯一二级索引列,这样就可以把访问被驱动表的成本降到更低了。
# 多表连接的成本分析
首先要考虑一下多表连接时可能产生出多少种连接顺序:
- 对于两表连接,比如表A和表B连接
只有 AB、BA这两种连接顺序。其实相当于 2 × 1 = 2 种连接顺序。
- 对于三表连接,比如表A、表B、表C进行连接
有ABC、ACB、BAC、BCA、CAB、CBA这么6种连接顺序。其实相当于 3 × 2 × 1 = 6 种连接顺序。
- 对于四表连接的话,则会有 4 × 3 × 2 × 1 = 24 种连接顺序。
- 对于 n 表连接的话,则有 n × (n-1) × (n-2) × ··· × 1 种连接顺序,就是n的阶乘种连接顺序,
也就是 n! 。
有 n 个表进行连接, MySQL 查询优化器要每一种连接顺序的成本都计算一遍么?那可是 n! 种连接顺序呀。其实真的是要都算一遍,不过设计 MySQL 的大叔们想了很多办法减少计算非常多种连接顺序的成本的方法:
- 提前结束某种顺序的成本评估
MySQL 在计算各种链接顺序的成本之前,会维护一个全局的变量,这个变量表示当前最小的连接查询成本。 如果在分析某个连接顺序的成本时,该成本已经超过当前最小的连接查询成本,那就压根儿不对该连接顺序继续往下分析了。
- 系统变量 optimizer_search_depth
为了防止无穷无尽的分析各种连接顺序的成本,设计 MySQL 的大叔们提出了 optimizer_search_depth 系统变量,表连接分析阈值。该值越大,成本分析的越精确,越容易得到好的执行计划,但是消耗的时间也就越长,否则得到不是很好的执行计划,但可以省掉很多分析连接成本的时间。
- 根据某些规则压根儿就不考虑某些连接顺序
启发式规则 (就是根据以往经验指定的一些规则),凡是不满足这些规则的 连接顺序压根儿就不分析他们提供了一个系统变量 optimizer_prune_level 来控制是否开启启发式规则。
# 调节成本常数
我们前边之介绍了两个 成本常数 :
- 读取一个页面花费的成本默认是 1.0
- 检测一条记录是否符合搜索条件的成本默认是 0.2
其实除了这两个成本常数, MySQL 还支持好多呢,它们被存储到了 mysql 数据库的两个表中:
mysql> SHOW TABLES FROM mysql LIKE '%cost%';
+--------------------------+
| Tables_in_mysql (%cost%) |
+--------------------------+
| engine_cost |
| server_cost |
+--------------------------+
2 rows in set (0.00 sec)
我们在第一章中就说过,一条语句的执行其实是分为两层的:
- server 层
- 存储引擎层
在 server 层进行连接管理、查询缓存、语法解析、查询优化等操作,在存储引擎层执行具体的数据存取操作。 也就是说一条语句在 server 层中执行的成本是和它操作的表使用的存储引擎是没关系的,所以关于这些操作对应的 成本常数 就存储在了 server_cost 表中,而依赖于存储引擎的一些操作对应的 成本常数 就存储在了 engine_cost 表中。
# mysql.server_cost表
server_cost 表中在 server 层进行的一些操作对应的 成本常数
mysql> SELECT * FROM mysql.server_cost;
+------------------------------+------------+---------------------+---------+
| cost_name | cost_value | last_update | comment |
+------------------------------+------------+---------------------+---------+
| disk_temptable_create_cost | NULL | 2018-01-20 12:03:21 | NULL |
| disk_temptable_row_cost | NULL | 2018-01-20 12:03:21 | NULL |
| key_compare_cost | NULL | 2018-01-20 12:03:21 | NULL |
| memory_temptable_create_cost | NULL | 2018-01-20 12:03:21 | NULL |
| memory_temptable_row_cost | NULL | 2018-01-20 12:03:21 | NULL |
| row_evaluate_cost | NULL | 2018-01-20 12:03:21 | NULL |
+------------------------------+------------+---------------------+---------+
6 rows in set (0.05 sec)
- cost_name
表示成本常数的名称。
- cost_value
表示成本常数对应的值。如果该列的值为 NULL 的话,意味着对应的成本常数会采用默认值。
- last_update
表示最后更新记录的时间。
- comment
注释。
目前在 server 层的一些操作对应的 成本常数 有以下几种
| 成本常数名称 | 默认值 | 描述 |
|---|---|---|
| disk_temptable_create_cost | 40.0 | 创建基于磁盘的临时表的成本,如果增大这个值的话会让优化器尽量少的创建基于磁盘的临时表。 |
| disk_temptable_row_cost | 1.0 | 向基于磁盘的临时表写入或读取一条记录的成本,如果增大这个值的话会让优化器尽量少的创建基于磁盘的临时表。 |
| key_compare_cost | 0.1 | 两条记录做比较操作的成本,多用在排序操作上,如果增大这个值的话会提升 filesort 的成本,让优化器可能更倾向于使用索引完成排序而不是 filesort 。 |
| memory_temptable_create_cost | 2.0 | 创建基于内存的临时表的成本,如果增大这个值的话会让优化器尽量少的创建基于内存的临时表。 |
| memory_temptable_row_cost | 0.2 | 向基于内存的临时表写入或读取一条记录的成本,如果增大这个值的话会让优化器尽量少的创建基于内存的临时表。 |
| row_evaluate_cost | 0.2 | 这个就是我们之前一直使用的检测一条记录是否符合搜索条件的成本,增大这个值可能让优化器更倾向于使用索引而不是直接全表扫描。 |
小贴士: MySQL在执行诸如DISTINCT查询、分组查询、Union查询以及某些特殊条件下的排序查询都可能在内部先创建一个临时表,使用这个临时表来辅助完成查询(比如对于DISTINCT查询可以建一个带有UNIQUE索引的临时表,直接把需要去重的记录插入到这个临时表中,插入完成之后的记录就是结果集了)。在数据量大的情况下可能创建基于磁盘的临时表,也就是为该临时表使用MyISAM、InnoDB等存储引擎,在数据量不大时可能创建基于内存的临时表,也就是使用Memory存储引擎。创建临时表和对这个临时表进行写入和读取的操作代价还是很高。
这些成本常数在 server_cost 中的初始值都是 NULL ,意味着优化器会使用它们的默认值来计算某个操作的成本,如果我们想修改某个成本常数的值的话,需要做两个步骤:
- 对我们感兴趣的成本常数做更新操作
比方说我们想把检测一条记录是否符合搜索条件的成本增大到 0.4 ,那么就可以这样写更新语句:
UPDATE mysql.server_cost
SET cost_value = 0.4
WHERE cost_name = 'row_evaluate_cost';
- 让系统重新加载这个表的值。
使用下边语句即可:
FLUSH OPTIMIZER_COSTS;
当然,在你修改完某个成本常数后想把它们再改回默认值的话,可以直接把 cost_value 的值设置为 NULL ,再使 用 FLUSH OPTIMIZER_COSTS 语句让系统重新加载它就好了。
# mysql.engine_cost表
engine_cost表 表中在存储引擎层进行的一些操作对应的 成本常数
mysql> SELECT * FROM mysql.engine_cost;
+-------------+-------------+------------------------+------------+---------------------+-
--------+
| engine_name | device_type | cost_name | cost_value | last_update |
comment |
+-------------+-------------+------------------------+------------+---------------------+-
--------+
| default | 0 | io_block_read_cost | NULL | 2018-01-20 12:03:21 |
NULL |
| default | 0 | memory_block_read_cost | NULL | 2018-01-20 12:03:21 |
NULL |
+-------------+-------------+------------------------+------------+---------------------+-
--------+
2 rows in set (0.05 sec)
- engine_name 列
指成本常数适用的存储引擎名称。如果该值为 default ,意味着对应的成本常数适用于所有的存储引擎。
- device_type 列
指存储引擎使用的设备类型,这主要是为了区分常规的机械硬盘和固态硬盘,不过在 MySQL 5.7.21 这个版本中并没有对机械硬盘的成本和固态硬盘的成本作区分,所以该值默认是 0 。
目前支持的存储引擎成本常数只有两个
| 成本常数名称 | 默认值 | 描述 |
|---|---|---|
| io_block_read_cost | 1.0 | 从磁盘上读取一个块对应的成本。请注意我使用的是块 ,而不是 页 这个词儿。对于InnoDB 存储引擎来说,一个 页 就是一个块,不过对于 MyISAM 存储引擎来说,默认是以4096 字节作为一个块的。增大这个值会加重 I/O 成本,可能让优化器更倾向于选择使用索引执行查询而不是执行全表扫描。 |
| memory_block_read_cost | 1.0 | 与上一个参数类似,只不过衡量的是从内存中读取一个块对应的成本。 |
# InnoDB统计数据是如何收集的
- InnoDB 以表为单位来收集统计数据,这些统计数据可以是基于磁盘的永久性统计数据,也可以是基于内存的非永久性统计数据。
- innodb_stats_persistent 控制着使用永久性统计数据还是非永久性统计数据; innodb_stats_persistent_sample_pages 控制着永久性统计数据的采样页面数量; innodb_stats_transient_sample_pages 控制着非永久性统计数据的采样页面数量; innodb_stats_auto_recalc 控制着是否自动重新计算统计数据。
- 我们可以针对某个具体的表,在创建和修改表时通过指定 STATS_PERSISTENT 、 STATS_AUTO_RECALC 、STATS_SAMPLE_PAGES 的值来控制相关统计数据属性。
- innodb_stats_method 决定着在统计某个索引列不重复值的数量时如何对待 NULL 值。
# Explain详解
| 列名 | 描述 |
|---|---|
| id | 在一个大的查询语句中每个SELECT 关键字都对应一个唯一的id |
| select_type | SELECT 关键字对应的那个查询的类型 |
| table | 表名 |
| partitions | 匹配的分区信息 |
| type | 针对单表的访问方法 |
| possible_keys | 可能用到的索引 |
| key | 实际上使用的索引 |
| key_len | 实际使用到的索引长度 |
| ref | 当使用索引列等值查询时,与索引列进行等值匹配的对象信息 |
| rows | 预估的需要读取的记录条数 |
| filtered | 某个表经过搜索条件过滤后剩余记录条数的百分比 |
| Extra | 一些额外的信息 |
CREATE TABLE single_table (
id INT NOT NULL AUTO_INCREMENT,
key1 VARCHAR(100),
key2 INT,
key3 VARCHAR(100),
key_part1 VARCHAR(100),
key_part2 VARCHAR(100),
key_part3 VARCHAR(100),
common_field VARCHAR(100),
PRIMARY KEY (id),
KEY idx_key1 (key1),
UNIQUE KEY idx_key2 (key2),
KEY idx_key3 (key3),
KEY idx_key_part(key_part1, key_part2, key_part3)
) Engine=InnoDB CHARSET=utf8;
我们仍然假设有两个和 single_table 表构造一模一样的 s1 、 s2 表,而且这两个表里边儿有10000条记录,除id列外其余的列都插入随机值。
# table
不论我们的查询语句有多复杂,里边儿包含了多少个表,到最后也是需要对每个表进行单表访问的,所以设计MySQL 的大叔规定EXPLAIN语句输出的每条记录都对应着某个单表的访问方法,该条记录的table列代表着该表的表名。
# 单表查询
mysql> explain select * from s1\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: s1
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 9636
filtered: 100.00
Extra: NULL
1 row in set, 1 warning (0.00 sec)
# 多表查询
mysql> explain select * from s1 inner join s2\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: s2
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 8646
filtered: 100.00
Extra: NULL
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: s1
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 9636
filtered: 100.00
Extra: Using join buffer (Block Nested Loop)
2 rows in set, 1 warning (0.00 sec)
# id
查询语句中每出现一个 SELECT 关键字,设计 MySQL 的大叔就会为它分配一个唯一的 id 值。这个 id 值就是 EXPLAIN 语句的第一个列,比如下边这个查询中只有一个 SELECT 关键字,所以 EXPLAIN 的结果中也就只有一 条 id 列为 1 的记录:
mysql> explain select * from s1 where key1 = 'a'\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: s1
partitions: NULL
type: ref
possible_keys: idx_key1
key: idx_key1
key_len: 303
ref: const
rows: 1
filtered: 100.00
Extra: NULL
1 row in set, 1 warning (0.06 sec)
对于连接查询来说,一个 SELECT 关键字后边的 FROM 子句中可以跟随多个表,所以在连接查询的执行计划中,每个表都会对应一条记录,但是这些记录的id值都是相同的,比如:
mysql> explain select * from s1 inner join s2\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: s2
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 8646
filtered: 100.00
Extra: NULL
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: s1
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 9636
filtered: 100.00
Extra: Using join buffer (Block Nested Loop)
2 rows in set, 1 warning (0.00 sec)
可以看到,上述连接查询中参与连接的 s1 和 s2 表分别对应一条记录,但是这两条记录对应的 id 值都是 1 。这里需要大家记住的是,在连接查询的执行计划中,每个表都会对应一条记录,这些记录的id列的值是相同的,出现在前边的表表示驱动表,出现在后边的表表示被驱动表。所以从上边 EXPLAIN 输出中我们可以看出,查询优 化器准备让 s2 表作为驱动表,让 s1 表作为被驱动表来执行查询。
对于包含子查询的查询语句来说,就可能涉及多个 SELECT 关键字,所以在包含子查询的查询语句的执行计划中,每个 SELECT 关键字都会对应一个唯一的 id 值,比如这样:
mysql> explain select * from s1 where key1 in (select key1 from s2) or key3 = 'a'\G
*************************** 1. row ***************************
id: 1
select_type: PRIMARY
table: s1
partitions: NULL
type: ALL
possible_keys: idx_key3
key: NULL
key_len: NULL
ref: NULL
rows: 9636
filtered: 100.00
Extra: Using where
*************************** 2. row ***************************
id: 2
select_type: SUBQUERY
table: s2
partitions: NULL
type: index
possible_keys: idx_key1
key: idx_key1
key_len: 303
ref: NULL
rows: 8646
filtered: 100.00
Extra: Using index
2 rows in set, 1 warning (0.05 sec)
从输出结果中我们可以看到, s1 表在外层查询中,外层查询有一个独立的 SELECT 关键字,所以第一条记录的 id 值就是 1 , s2 表在子查询中,子查询有一个独立的 SELECT 关键字,所以第二条记录的 id 值就是 2 。
但是这里大家需要特别注意,查询优化器可能对涉及子查询的查询语句进行重写,从而转换为连接查询。所以如果我们想知道查询优化器对某个包含子查询的语句是否进行了重写,直接查看执行计划的不同表的id是否相同就好了
对于包含 UNION 子句的查询语句来说,每个 SELECT 关键字对应一个 id 值也是没错的,不过还是有点儿特别的 东西,比方说下边这个查询:
mysql> explain select * from s1 union select * from s2\G
*************************** 1. row ***************************
id: 1
select_type: PRIMARY
table: s1
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 9636
filtered: 100.00
Extra: NULL
*************************** 2. row ***************************
id: 2
select_type: UNION
table: s2
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 8646
filtered: 100.00
Extra: NULL
*************************** 3. row ***************************
id: NULL
select_type: UNION RESULT
table: <union1,2>
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: NULL
filtered: NULL
Extra: Using temporary
3 rows in set, 1 warning (0.00 sec)
UNION 就是将查询的多个结果集合并起来并结果集进行去重,怎么去重? MySQL 使用的是内部的临时表。正如上边的查询计划中所示, UNION 子句是为了把 id 为 1 的查询和 id 为 2 的查询的 结果集合并起来并去重,所以在内部创建了一个名为 <union1, 2> 的临时表(就是执行计划第三条记录的 table 列的名称), id 为 NULL 表明这个临时表是为了合并两个查询的结果集而创建的。
跟 UNION 对比起来, UNION ALL 就不需要为最终的结果集进行去重,它只是单纯的把多个查询的结果集中的记录合并成一个并返回给用户,所以也就不需要使用临时表。所以在包含 UNION ALL 子句的查询的执行计划中,就没有那个 id 为 NULL 的记录,如下所示:
mysql> explain select * from s1 union all select * from s2\G
*************************** 1. row ***************************
id: 1
select_type: PRIMARY
table: s1
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 9636
filtered: 100.00
Extra: NULL
*************************** 2. row ***************************
id: 2
select_type: UNION
table: s2
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 8646
filtered: 100.00
Extra: NULL
2 rows in set, 1 warning (0.01 sec)
# select_type
通过上边的内容我们知道,一条大的查询语句里边可以包含若干个 SELECT 关键字,每个 SELECT 关键字代表着一个小的查询语句,而每个 SELECT 关键字的 FROM 子句中都可以包含若干张表(这些表用来做连接查询),每一张表都对应着执行计划输出中的一条记录,对于在同一个 SELECT 关键字中的表来说,它们的 id 值是相同的。 设计 MySQL 的大叔为每一个 SELECT 关键字代表的小查询都定义了一个称之为 select_type 的属性,意思是我们 只要知道了某个小查询的 select_type 属性,就知道了这个小查询在整个大查询中扮演了一个什么角色
设计 MySQL 的大叔把将子查询结果集中的记录保存到临时表的过程称之为 物化 (英文名:Materialize )
| _select_type _值 | JSON 名称 | 意义 |
|---|---|---|
| SIMPLE | 没有任何 | 简单SELECT (opens new window)(不使用 UNION (opens new window)或子查询) |
| PRIMARY | 没有任何 | 最外层SELECT (opens new window) |
| UNION (opens new window) | 没有任何 | UNION (opens new window) 中的第二个或以后的SELECT (opens new window)语句, |
| DEPENDENT UNION | dependent( true) | UNION (opens new window) 中的第二个或以后的SELECT (opens new window)语句,取决于外部查询 |
| UNION RESULT | union_result | UNION (opens new window)的结果 |
| SUBQUERY (opens new window) | 没有任何 | 首先SELECT (opens new window)在子查询中 |
| DEPENDENT SUBQUERY | dependent( true) | 首先SELECT (opens new window)在子查询中,依赖于外部查询 |
| DERIVED | 没有任何 | 派生表 |
| MATERIALIZED | materialized_from_subquery | 物化子查询 |
| UNCACHEABLE SUBQUERY | cacheable( false) | 一个子查询,其结果无法缓存,必须为外部查询的每一行重新计算 |
| UNCACHEABLE UNION | cacheable( false) | UNION (opens new window) 属于不可缓存子查询 的第二个或以后的选择(请参阅 参考资料UNCACHEABLE SUBQUERY) |
- SIMPLE
查询语句中不包含 UNION 或者子查询的查询都算作是 SIMPLE 类型,当然,连接查询也算是 SIMPLE 类型,比如:
mysql> explain select * from s1 join s2;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+---------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+---------------------------------------+
| 1 | SIMPLE | s2 | NULL | ALL | NULL | NULL | NULL | NULL | 8646 | 100.00 | NULL |
| 1 | SIMPLE | s1 | NULL | ALL | NULL | NULL | NULL | NULL | 9636 | 100.00 | Using join buffer (Block Nested Loop) |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+---------------------------------------+
2 rows in set, 1 warning (0.03 sec)
- PRIMARY 对于包含 UNION 、 UNION ALL 或者子查询的大查询来说,它是由几个小查询组成的,其中最左边的那个查询的 select_type 值就是 PRIMARY ,比方说:
mysql> explain select * from s1 union select * from s2;
+----+--------------+------------+------------+------+---------------+------+---------+------+------+----------+-----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+--------------+------------+------------+------+---------------+------+---------+------+------+----------+-----------------+
| 1 | PRIMARY | s1 | NULL | ALL | NULL | NULL | NULL | NULL | 9636 | 100.00 | NULL |
| 2 | UNION | s2 | NULL | ALL | NULL | NULL | NULL | NULL | 8646 | 100.00 | NULL |
| NULL | UNION RESULT | <union1,2> | NULL | ALL | NULL | NULL | NULL | NULL | NULL | NULL | Using temporary |
+----+--------------+------------+------------+------+---------------+------+---------+------+------+----------+-----------------+
3 rows in set, 1 warning (0.00 sec)
从结果中可以看到,最左边的小查询 SELECT * FROM s1 对应的是执行计划中的第一条记录,它的select type 值就是 PRIMARY 。
- UNION 对于包含 UNION 或者 UNION ALL 的大查询来说,它是由几个小查询组成的,其中除了最左边的那个小查询以外,其余的小查询的 select_type 值就是 UNION ,可以对比上一个例子的效果,这就不多举例子了。
- UNION RESULT
MySQL 选择使用临时表来完成 UNION 查询的去重工作,针对该临时表的查询的 select_type 就是 UNION RESULT ,例子上边有,就不赘述了。
- SUBQUERY
如果包含子查询的查询语句不能够转为对应的 semi-join 的形式,并且该子查询是不相关子查询,并且查询优化器决定采用将该子查询物化的方案来执行该子查询时,该子查询的第一个 SELECT 关键字代表的那个查询的 select_type 就是 SUBQUERY ,比如下边这个查询:
mysql> explain select * from s1 where key1 in (select key1 from s2) or key3 = 'a';
+----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+-------------+
| 1 | PRIMARY | s1 | NULL | ALL | idx_key3 | NULL | NULL | NULL | 9636 | 100.00 | Using where |
| 2 | SUBQUERY | s2 | NULL | index | idx_key1 | idx_key1 | 303 | NULL | 8646 | 100.00 | Using index |
+----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+-------------+
2 rows in set, 1 warning (0.12 sec)
由于select_type为SUBQUERY的子查询由于会被物化,所以只需要执行一遍。
- DEPENDENT SUBQUERY 如果包含子查询的查询语句不能够转为对应的 semi-join 的形式,并且该子查询是相关子查询,则该子查询的第一个 SELECT 关键字代表的那个查询的 select_type 就是 DEPENDENT SUBQUERY ,比如下边这个查询:
mysql> explain select * from s1 where key1 in (select key1 from s2 where s1.key2 = s2.key2) or key3 = 'a';
+----+--------------------+-------+------------+------+-------------------+----------+---------+-----------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+--------------------+-------+------------+------+-------------------+----------+---------+-----------------+------+----------+-------------+
| 1 | PRIMARY | s1 | NULL | ALL | idx_key3 | NULL | NULL | NULL | 9636 | 100.00 | Using where |
| 2 | DEPENDENT SUBQUERY | s2 | NULL | ref | idx_key2,idx_key1 | idx_key2 | 5 | test_db.s1.key2 | 1 | 10.00 | Using where |
+----+--------------------+-------+------------+------+-------------------+----------+---------+-----------------+------+----------+-------------+
2 rows in set, 2 warnings (0.03 sec)
select_type为DEPENDENT SUBQUERY的查询可能会被执行多次
- DEPENDENT UNION
在包含 UNION 或者 UNION ALL 的大查询中,如果各个小查询都依赖于外层查询的话,那除了最左边的那个小查询之外,其余的小查询的 select_type 的值就是 DEPENDENT UNION 。
mysql> explain select * from s1 where key1 in (select key1 from s2 where key1 = 'a' union select key1 from s1 where key1 = 'b');
+----+--------------------+------------+------------+------+---------------+----------+---------+-------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+--------------------+------------+------------+------+---------------+----------+---------+-------+------+----------+--------------------------+
| 1 | PRIMARY | s1 | NULL | ALL | NULL | NULL | NULL | NULL | 9636 | 100.00 | Using where |
| 2 | DEPENDENT SUBQUERY | s2 | NULL | ref | idx_key1 | idx_key1 | 303 | const | 1 | 100.00 | Using where; Using index |
| 3 | DEPENDENT UNION | s1 | NULL | ref | idx_key1 | idx_key1 | 303 | const | 1 | 100.00 | Using where; Using index |
| NULL | UNION RESULT | <union2,3> | NULL | ALL | NULL | NULL | NULL | NULL | NULL | NULL | Using temporary |
+----+--------------------+------------+------------+------+---------------+----------+---------+-------+------+----------+--------------------------+
4 rows in set, 1 warning (0.12 sec)
这个查询比较复杂啊,大查询里包含了一个子查询,子查询里又是由 UNION 连起来的两个小查询。从执行计划中可以看出来, SELECT key1 FROM s2 WHERE key1 = 'a' 这个小查询由于是子查询中第一个查询,所以 它的 select_type 是DEPENDENT SUBQUERY ,而 SELECT key1 FROM s1 WHERE key1 = 'b' 这个查询的select_type 就是 DEPENDENT UNION 。
- DERIVED
对于采用物化的方式执行的包含派生表的查询,该派生表对应的子查询的 select_type 就是 DERIVED ,比方 说下边这个查询:
mysql> explain select * from (select key1,count(*) as c from s1 group by key1) as derived_s1 where c > 1;
+----+-------------+------------+------------+-------+---------------+----------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+-------+---------------+----------+---------+------+------+----------+-------------+
| 1 | PRIMARY | <derived2> | NULL | ALL | NULL | NULL | NULL | NULL | 9636 | 33.33 | Using where |
| 2 | DERIVED | s1 | NULL | index | idx_key1 | idx_key1 | 303 | NULL | 9636 | 100.00 | Using index |
+----+-------------+------------+------------+-------+---------------+----------+---------+------+------+----------+-------------+
2 rows in set, 1 warning (0.08 sec)
从执行计划中可以看出, id 为 2 的记录就代表子查询的执行方式,它的 select_type 是 DERIVED ,说明该子查询是以物化的方式执行的。 id 为 1 的记录代表外层查询,大家注意看它的 table 列显示的是<derived2> ,表示该查询是针对将派生表物化之后的表进行查询的。
- MATERIALIZED
当查询优化器在执行包含子查询的语句时,选择将子查询物化之后与外层查询进行连接查询时,该子查询对应的 select_type 属性就是 MATERIALIZED ,比如下边这个查询:
mysql> explain select * from s1 where key1 in (select key1 from s2);
+----+--------------+-------------+------------+--------+---------------+------------+---------+-----------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+--------------+-------------+------------+--------+---------------+------------+---------+-----------------+------+----------+-------------+
| 1 | SIMPLE | s1 | NULL | ALL | idx_key1 | NULL | NULL | NULL | 9636 | 100.00 | Using where |
| 1 | SIMPLE | <subquery2> | NULL | eq_ref | <auto_key> | <auto_key> | 303 | test_db.s1.key1 | 1 | 100.00 | NULL |
| 2 | MATERIALIZED | s2 | NULL | index | idx_key1 | idx_key1 | 303 | NULL | 8646 | 100.00 | Using index |
+----+--------------+-------------+------------+--------+---------------+------------+---------+-----------------+------+----------+-------------+
3 rows in set, 1 warning (0.01 sec)
执行计划的第三条记录的 id 值为 2 ,说明该条记录对应的是一个单表查询,从它的 select_type 值为MATERIALIZED 可以看出,查询优化器是要把子查询先转换成物化表。然后看执行计划的前两条记录的 id 值 都为 1 ,说明这两条记录对应的表进行连接查询,需要注意的是第二条记录的 table 列的值是<subquery2> ,说明该表其实就是 id 为 2 对应的子查询执行之后产生的物化表,然后将 s1 和该物化表进行连接查询。
# type
通过什么方法来访问这个表
- system 该表只有一行(= 系统表)。 这是 const 连接类型的一个特例。 当表中只有一条记录并且该表使用的存储引擎的统计数据是精确的,比如MyISAM、Memory,那么对该表的访问方法就是 system 。
mysql> explain select * from (select 1 = 1) temp;
+----+-------------+------------+------------+--------+---------------+------+---------+------+------+----------+----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+--------+---------------+------+---------+------+------+----------+----------------+
| 1 | PRIMARY | <derived2> | NULL | system | NULL | NULL | NULL | NULL | 1 | 100.00 | NULL |
| 2 | DERIVED | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | No tables used |
+----+-------------+------------+------------+--------+---------------+------+---------+------+------+----------+----------------+
2 rows in set, 1 warning (0.00 sec)
子查询的结果生成临时表,在内存中,相当于Memory引擎
- const 根据主键或者唯一二级索引列与常数进行等值匹配时,对单表的访问方法就是 const
mysql> explain select * from s1 where id =5;
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| 1 | SIMPLE | s1 | NULL | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | NULL |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.08 sec)
- eq_ref
对于先前表中的每个行组合,从该表(被驱动表)中读取一行。 除了 system 和 const 类型之外,这是最好的连接类型。 当连接使用索引的所有部分并且索引是 PRIMARY KEY 或 UNIQUE NOT NULL 索引时使用它。
mysql> explain select * from s1 inner join s2 on s1.id = s2.id;
+----+-------------+-------+------------+--------+---------------+---------+---------+---------------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+--------+---------------+---------+---------+---------------+------+----------+-------+
| 1 | SIMPLE | s2 | NULL | ALL | PRIMARY | NULL | NULL | NULL | 8646 | 100.00 | NULL |
| 1 | SIMPLE | s1 | NULL | eq_ref | PRIMARY | PRIMARY | 4 | test_db.s2.id | 1 | 100.00 | NULL |
+----+-------------+-------+------------+--------+---------------+---------+---------+---------------+------+----------+-------+
2 rows in set, 1 warning (0.00 sec)
s2驱动表,s1被驱动表,与s1的主键进行匹配,是primary key,主键不会冲突,就只匹配一条数据
- ref 对于先前表中的每个行组合,从该表中读取具有匹配索引值的所有行。 如果连接仅使用键的最左侧前缀,或者如果键不是 PRIMARY KEY 或 UNIQUE NOT NULL 索引(换句话说,如果连接不能基于键值选择单行),则使用 ref。 如果使用的键只匹配几行,这是一个很好的连接类型。ref 可用于使用 = 或 <=> 运算符比较的索引列。
mysql> explain select * from s1 inner join s2 on s1.key2 = s2.key2;
+----+-------------+-------+------------+------+---------------+----------+---------+-----------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+----------+---------+-----------------+------+----------+-------------+
| 1 | SIMPLE | s2 | NULL | ALL | idx_key2 | NULL | NULL | NULL | 8646 | 100.00 | Using where |
| 1 | SIMPLE | s1 | NULL | ref | idx_key2 | idx_key2 | 5 | test_db.s2.key2 | 1 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+----------+---------+-----------------+------+----------+-------------+
2 rows in set, 1 warning (0.00 sec)
mysql> show index from s1;
+-------+------------+--------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+-------+------------+--------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| s1 | 0 | PRIMARY | 1 | id | A | 9636 | NULL | NULL | | BTREE | | |
| s1 | 0 | idx_key2 | 1 | key2 | A | 9636 | NULL | NULL | YES | BTREE | | |
| s1 | 1 | idx_key1 | 1 | key1 | A | 9636 | NULL | NULL | YES | BTREE | | |
| s1 | 1 | idx_key3 | 1 | key3 | A | 9636 | NULL | NULL | YES | BTREE | | |
| s1 | 1 | idx_key_part | 1 | key_part1 | A | 9256 | NULL | NULL | YES | BTREE | | |
| s1 | 1 | idx_key_part | 2 | key_part2 | A | 9636 | NULL | NULL | YES | BTREE | | |
| s1 | 1 | idx_key_part | 3 | key_part3 | A | 9636 | NULL | NULL | YES | BTREE | | |
+-------+------------+--------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
7 rows in set (0.23 sec)
虽然key2是UNIQUE索引,但是可以存在多个null的字段(相当于有重复的),不能匹配一行,所以是ref
- fulltext 全文索引
- ref_or_null
当对普通二级索引进行等值匹配查询,该索引列的值也可以是 NULL 值时,那么对该表的访问方法就可能是ref_or_null
mysql> explain select * from s1 inner join s2 on s1.key3 = s2.key3 or s2.key3 is null;
+----+-------------+-------+------------+-------------+---------------+----------+---------+-----------------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------------+---------------+----------+---------+-----------------+------+----------+-----------------------+
| 1 | SIMPLE | s1 | NULL | ALL | idx_key3 | NULL | NULL | NULL | 9636 | 100.00 | NULL |
| 1 | SIMPLE | s2 | NULL | ref_or_null | idx_key3 | idx_key3 | 303 | test_db.s1.key3 | 2 | 100.00 | Using index condition |
+----+-------------+-------+------------+-------------+---------------+----------+---------+-----------------+------+----------+-----------------------+
2 rows in set, 1 warning (0.00 sec)
- index_merge 一般情况下对于某个表的查询只能使用到一个索引,但单表访问方法时在某些场景下可以使用 Intersection 、 Union 、 Sort-Union 这三种索引合并的方式来执行查询
mysql> explain select * from s1 where id = 'a' or key3 = 'a';
+----+-------------+-------+------------+-------------+------------------+------------------+---------+------+------+----------+--------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------------+------------------+------------------+---------+------+------+----------+--------------------------------------------+
| 1 | SIMPLE | s1 | NULL | index_merge | PRIMARY,idx_key3 | PRIMARY,idx_key3 | 4,303 | NULL | 2 | 100.00 | Using union(PRIMARY,idx_key3); Using where |
+----+-------------+-------+------------+-------------+------------------+------------------+---------+------+------+----------+--------------------------------------------+
1 row in set, 1 warning (0.00 sec)
- unique_subquery 类似于两表连接中被驱动表的 eq_ref 访问方法, unique_subquery 是针对在一些包含 IN 子查询的查询语句中,如果查询优化器决定将 IN 子查询转换为 EXISTS 子查询,而且子查询可以使用到主键进行等值匹配的话,那么该子查询执行计划的 type 列的值就是 unique_subquery
mysql> explain select * from s1 where key2 in (select id from s2 where s1.key1 = s2.key1) or key3 = 'a';
+----+--------------------+-------+------------+-----------------+------------------+---------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+--------------------+-------+------------+-----------------+------------------+---------+---------+------+------+----------+-------------+
| 1 | PRIMARY | s1 | NULL | ALL | idx_key3 | NULL | NULL | NULL | 9636 | 100.00 | Using where |
| 2 | DEPENDENT SUBQUERY | s2 | NULL | unique_subquery | PRIMARY,idx_key1 | PRIMARY | 4 | func | 1 | 10.00 | Using where |
+----+--------------------+-------+------------+-----------------+------------------+---------+---------+------+------+----------+-------------+
2 rows in set, 2 warnings (0.00 sec)
执行子查询时会用到 id 列的索引(主键索引)
_value _IN ( SELECT _primary_key _FROM _single_table _WHERE _some_expr _) https://dev.mysql.com/doc/refman/5.7/en/explain-output.html#jointype_unique_subquery (opens new window)
- index_subquery index_subquery 与 unique_subquery 类似,只不过访问子查询中的表时使用的是普通的索引
mysql> explain select * from s1 where key2 in (select key2 from s2 where s1.key1 = s2.key1) or key3 = 'a';
+----+--------------------+-------+------------+----------------+-------------------+----------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+--------------------+-------+------------+----------------+-------------------+----------+---------+------+------+----------+-------------+
| 1 | PRIMARY | s1 | NULL | ALL | idx_key3 | NULL | NULL | NULL | 9636 | 100.00 | Using where |
| 2 | DEPENDENT SUBQUERY | s2 | NULL | index_subquery | idx_key2,idx_key1 | idx_key2 | 5 | func | 1 | 10.00 | Using where |
+----+--------------------+-------+------------+----------------+-------------------+----------+---------+------+------+----------+-------------+
2 rows in set, 2 warnings (0.00 sec)
- range 如果使用索引获取某些 范围区间 的记录,那么就可能使用到 range 访问方法
mysql> explain select * from s1 where key1 in ('a','b','c');
+----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | s1 | NULL | range | idx_key1 | idx_key1 | 303 | NULL | 3 | 100.00 | Using index condition |
+----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+-----------------------+
1 row in set, 1 warning (0.24 sec)
mysql> explain select * from s1 where key1 > 'a' and key1 < 'b';
+----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | s1 | NULL | range | idx_key1 | idx_key1 | 303 | NULL | 525 | 100.00 | Using index condition |
+----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+-----------------------+
1 row in set, 1 warning (0.03 sec)
- index 当我们可以使用索引覆盖,但需要扫描全部的索引记录时,该表的访问方法就是 index
mysql> show index from s1;
+-------+------------+--------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+-------+------------+--------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| s1 | 0 | PRIMARY | 1 | id | A | 9636 | NULL | NULL | | BTREE | | |
| s1 | 0 | idx_key2 | 1 | key2 | A | 9636 | NULL | NULL | YES | BTREE | | |
| s1 | 1 | idx_key1 | 1 | key1 | A | 9636 | NULL | NULL | YES | BTREE | | |
| s1 | 1 | idx_key3 | 1 | key3 | A | 9636 | NULL | NULL | YES | BTREE | | |
| s1 | 1 | idx_key_part | 1 | key_part1 | A | 9256 | NULL | NULL | YES | BTREE | | |
| s1 | 1 | idx_key_part | 2 | key_part2 | A | 9636 | NULL | NULL | YES | BTREE | | |
| s1 | 1 | idx_key_part | 3 | key_part3 | A | 9636 | NULL | NULL | YES | BTREE | | |
+-------+------------+--------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
7 rows in set (0.21 sec)
mysql> explain select key_part2 from s1 where key_part3 = 'a';
+----+-------------+-------+------------+-------+---------------+--------------+---------+------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+--------------+---------+------+------+----------+--------------------------+
| 1 | SIMPLE | s1 | NULL | index | NULL | idx_key_part | 909 | NULL | 9636 | 10.00 | Using where; Using index |
+----+-------------+-------+------------+-------+---------------+--------------+---------+------+------+----------+--------------------------+
1 row in set, 1 warning (0.02 sec)
上述查询中的搜索列表中只有 key_part2 一个列,而且搜索条件中也只有 key_part3 一个列,这两个列又恰好包含在 idx_key_part 这个索引中,可是搜索条件 key_part3 不能直接使用该索引进行 ref 或者 range 方 式的访问,只能扫描整个 idx_key_part 索引的记录,所以查询计划的 type 列的值就是 index 。
:::success
小贴士:
再一次强调,对于使用InnoDB存储引擎的表来说,二级索引的记录只包含索引列和主键列的值,而聚簇索引中包含用户定义的全部列以及一些隐藏列,所以扫描二级索引的代价比直接全表扫描, 也就是扫描聚簇索引的代价更低一些。
:::
- ALL
全表扫描
一般来说,这些访问方法按照我们介绍它们的顺序性能依次变差。其中除了 All 这个访问方法外,其余的访问方法都能用到索引,除了 index_merge 访问方法外,其余的访问方法都最多只能用到一个索引。
# possible_keys和key
possible_keys 列表示在某个查询语句中,对某个表执行单表查询时可能用到的索引有哪些, key 列表示实际用到的索引有哪些
mysql> explain select * from s1 where key1 > 'z' and key3 = 'a';
+----+-------------+-------+------------+------+-------------------+----------+---------+-------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+-------------------+----------+---------+-------+------+----------+-------------+
| 1 | SIMPLE | s1 | NULL | ref | idx_key1,idx_key3 | idx_key3 | 303 | const | 1 | 5.00 | Using where |
+----+-------------+-------+------------+------+-------------------+----------+---------+-------+------+----------+-------------+
1 row in set, 1 warning (0.01 sec)
上述执行计划的 possible_keys 列的值是 idx_key1,idx_key3 ,表示该查询可能使用到 idx_key1,idx_key3 两个索引,然后 key 列的值是 idx_key3 ,表示经过查询优化器计算使用不同索引的成本后,最后决定使用idx_key3 来执行查询比较划算。
不过有一点比较特别,就是在使用 index 访问方法来查询某个表时, possible_keys 列是空的,而 key 列展示的是实际使用到的索引,比如这样:
mysql> explain select key_part2 from s1 where key_part3 = 'a';
+----+-------------+-------+------------+-------+---------------+--------------+---------+------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+--------------+---------+------+------+----------+--------------------------+
| 1 | SIMPLE | s1 | NULL | index | NULL | idx_key_part | 909 | NULL | 9636 | 10.00 | Using where; Using index |
+----+-------------+-------+------------+-------+---------------+--------------+---------+------+------+----------+--------------------------+
1 row in set, 1 warning (0.00 sec)
:::info 另外需要注意的一点是,possible_keys列中的值并不是越多越好,可能使用的索引越多,查询优化器计算查询成 本时就得花费更长时间,所以如果可以的话,尽量删除那些用不到的索引。 :::
# key_len
key_len 列表示当优化器决定使用某个索引执行查询时,该索引记录的最大长度(字节),它是由这三个部分构成的:
- 对于使用固定长度类型的索引列来说,它实际占用的存储空间的最大长度就是该固定值,对于指定字符集的变长类型的索引列来说,比如某个索引列的类型是 VARCHAR(100) ,使用的字符集是 utf8 ,那么该列实际占 用的最大存储空间就是 100 × 3 = 300 个字节。
- 如果该索引列可以存储 NULL 值,则 key_len 比不可以存储 NULL 值时多1个字节。
- 对于变长字段来说,都会有2个字节的空间来存储该变长列的实际长度。
mysql> desc s1;
+--------------+--------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------------+--------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| key1 | varchar(100) | YES | MUL | NULL | |
| key2 | int(11) | YES | UNI | NULL | |
| key3 | varchar(100) | YES | MUL | NULL | |
| key_part1 | varchar(100) | YES | MUL | NULL | |
| key_part2 | varchar(100) | YES | | NULL | |
| key_part3 | varchar(100) | YES | | NULL | |
| common_field | varchar(100) | YES | | NULL | |
+--------------+--------------+------+-----+---------+----------------+
8 rows in set (0.38 sec)
mysql> explain select * from s1 where id = 5;
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| 1 | SIMPLE | s1 | NULL | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | NULL |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.04 sec)
由于 id 列的类型是 INT ,并且不可以存储 NULL 值,所以在使用该列的索引时 key_len 大小就是 4 。
当索引列可以存储 NULL 值时,比如:
mysql> EXPLAIN SELECT * FROM s1 WHERE key2 = 482734012;
+----+-------------+-------+------------+-------+---------------+----------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+----------+---------+-------+------+----------+-------+
| 1 | SIMPLE | s1 | NULL | const | idx_key2 | idx_key2 | 5 | const | 1 | 100.00 | NULL |
+----+-------------+-------+------------+-------+---------------+----------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.03 sec)
可以看到 key_len 列就变成了 5 ,比使用 id 列的索引时多了 1 。
对于可变长度的索引列来说,比如下边这个查询:
mysql> explain select * from s1 where key1 = 'a';
+----+-------------+-------+------------+------+---------------+----------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+----------+---------+-------+------+----------+-------+
| 1 | SIMPLE | s1 | NULL | ref | idx_key1 | idx_key1 | 303 | const | 1 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+----------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.03 sec)
由于 key1 列的类型是 VARCHAR(100) ,所以该列实际最多占用的存储空间就是 300 字节,又因为该列允许存储NULL 值,所以 key_len 需要加 1 ,又因为该列是可变长度列,所以 key_len 需要加 2 ,所以最后 ken_len 的 值就是 303 。
在执行计划中输出 key_len 列主要是为了让我们区分某个使用联合索引的查询具体用了几个索引列,而不是为了准确的说明针对某个具体存储引擎存储变长字段的实际长度占用的空间到底是占用1个字节还是2个字节。
mysql> explain select * from s1 where key_part1 = 'a';
+----+-------------+-------+------------+------+---------------+--------------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+--------------+---------+-------+------+----------+-------+
| 1 | SIMPLE | s1 | NULL | ref | idx_key_part | idx_key_part | 303 | const | 1 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+--------------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.08 sec)
mysql> explain select * from s1 where key_part1 = 'a' and key_part2 = 'b';
+----+-------------+-------+------------+------+---------------+--------------+---------+-------------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+--------------+---------+-------------+------+----------+-------+
| 1 | SIMPLE | s1 | NULL | ref | idx_key_part | idx_key_part | 606 | const,const | 1 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+--------------+---------+-------------+------+----------+-------+
1 row in set, 1 warning (0.02 sec)
第一次查询 key_len 列中看到值是 303 ,这意味着 MySQL 在执行上述查询中只能用到 idx_key_part索引的一个索引列 第二次查询 ken_len 列的值是 606 ,说明执行这个查询的时候可以用到联合索引 idx_key_part 的两 个索引列。
# ref
当使用索引列等值匹配的条件去执行查询时,也就是在访问方法是 const 、 eq_ref 、 ref 、 ref_or_null 、unique_subquery 、 index_subquery 其中之一时, ref 列展示的就是与索引列作等值匹配的东东是个啥,比如 只是一个常数或者是某个列。大家看下边这个查询:
mysql> explain select * from s1 where key1 = 'a';
+----+-------------+-------+------------+------+---------------+----------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+----------+---------+-------+------+----------+-------+
| 1 | SIMPLE | s1 | NULL | ref | idx_key1 | idx_key1 | 303 | const | 1 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+----------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.26 sec)
可以看到 ref 列的值是 const ,表明在使用 idx_key1 索引执行查询时,与 key1 列作等值匹配的对象是一个常数,当然有时候更复杂一点:
mysql> explain select * from s1 inner join s2 on s1.id = s2.id;
+----+-------------+-------+------------+--------+---------------+---------+---------+---------------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+--------+---------------+---------+---------+---------------+------+----------+-------+
| 1 | SIMPLE | s2 | NULL | ALL | PRIMARY | NULL | NULL | NULL | 8646 | 100.00 | NULL |
| 1 | SIMPLE | s1 | NULL | eq_ref | PRIMARY | PRIMARY | 4 | test_db.s2.id | 1 | 100.00 | NULL |
+----+-------------+-------+------------+--------+---------------+---------+---------+---------------+------+----------+-------+
2 rows in set, 1 warning (0.79 sec)
可以看到对被驱动表 s1 的访问方法是 eq_ref ,而对应的 ref 列的值是 test_db.s2.id ,这说明在对被驱动表进行访问时会用到 PRIMARY 索引,也就是聚簇索引与一个列进行等值匹配的条件,于 s2 表的 id 作等值匹配的对象就是 test_db.s2.id 列(注意这里把数据库名也写出来了)。
有的时候与索引列进行等值匹配的对象是一个函数,比方说下边这个查询:
mysql> explain select * from s1 inner join s2 on s1.key1 = upper(s2.key1);
+----+-------------+-------+------------+------+---------------+----------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+----------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | s2 | NULL | ALL | NULL | NULL | NULL | NULL | 8646 | 100.00 | NULL |
| 1 | SIMPLE | s1 | NULL | ref | idx_key1 | idx_key1 | 303 | func | 1 | 100.00 | Using index condition |
+----+-------------+-------+------------+------+---------------+----------+---------+------+------+----------+-----------------------+
2 rows in set, 1 warning (0.09 sec)
我们看执行计划的第二条记录,可以看到对 s2 表采用 ref 访问方法执行查询,然后在查询计划的 ref 列里输出的是 func ,说明与 s2 表的 key1 列进行等值匹配的对象是一个函数。
# rows
如果查询优化器决定使用全表扫描的方式对某个表执行查询时,执行计划的 rows 列就代表预计需要扫描的行数,如果使用索引来执行查询时,执行计划的 rows 列就代表预计扫描的索引记录行数。
mysql> explain select * from s1 where key1 > 'd';
+----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | s1 | NULL | range | idx_key1 | idx_key1 | 303 | NULL | 1636 | 100.00 | Using index condition |
+----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)
我们看到执行计划的 rows 列的值是 1636,这意味着查询优化器在经过分析使用 idx_key1 进行查询的成本之后,觉得(大概)满足 key1 > 'd' 这个条件的记录只有 1636 条。
# filtered
之前在分析连接查询的成本时提出过一个 condition filtering 的概念,就是 MySQL 在计算驱动表扇出时采用的 一个策略:
- 如果使用的是全表扫描的方式执行的单表查询,那么计算驱动表扇出时需要估计出满足搜索条件的记录到底有多少条。
- 如果使用的是索引执行的单表扫描,那么计算驱动表扇出的时候需要估计出满足除使用到对应索引的搜索条件外的其他搜索条件的记录有多少条。
mysql> explain select * from s1 where key1 > 'd' and common_field = 'a';
+----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+------------------------------------+
| 1 | SIMPLE | s1 | NULL | range | idx_key1 | idx_key1 | 303 | NULL | 1636 | 10.00 | Using index condition; Using where |
+----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+------------------------------------+
1 row in set, 1 warning (0.00 sec)
从执行计划的 key 列中可以看出来,该查询使用 idx_key1 索引来执行查询,从 rows 列可以看出满足 key1 > 'd' 的记录有 1636 条。执行计划的 filtered 列就代表查询优化器预测在这 1636 条记录中,有多少条记录满足其余的搜索条件,也就是 common_field = 'a' 这个条件的百分比。此处 filtered 列的值是 10.00 ,说明查询优 化器预测在 1636 条记录中有 10.00% 的记录满足 common_field = 'a' 这个条件。
对于单表查询来说,这个 filtered 列的值没什么意义,我们更关注在连接查询中驱动表对应的执行计划记录的 filtered 值,比方说下边这个查询:
mysql> explain select * from s1 inner join s2 on s1.key1 = s2.key1 where s1.common_field = 'a';
+----+-------------+-------+------------+------+---------------+----------+---------+-----------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+----------+---------+-----------------+------+----------+-------------+
| 1 | SIMPLE | s1 | NULL | ALL | idx_key1 | NULL | NULL | NULL | 9636 | 10.00 | Using where |
| 1 | SIMPLE | s2 | NULL | ref | idx_key1 | idx_key1 | 303 | test_db.s1.key1 | 1 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+----------+---------+-----------------+------+----------+-------------+
2 rows in set, 1 warning (0.00 sec)
从执行计划中可以看出来,查询优化器打算把 s1 当作驱动表, s2 当作被驱动表。我们可以看到驱动表 s1 表的执行计划的 rows 列为 9636, filtered 列为 10.00 ,这意味着驱动表 s1 的扇出值就是 9636 × 10.00% = 963.6 ,这说明还要对被驱动表执行大约 963 次查询。
# Extra
顾名思义, Extra 列是用来说明一些额外信息的,我们可以通过这些额外信息来更准确的理解 MySQL 到底将如何执行给定的查询语句。 MySQL 提供的额外信息有好几十个,我们只挑一些平时常见的或者比较重要的额外信息介绍给大家。
- No tables used
当查询语句的没有
FROM子句时将会提示该额外信息
mysql> explain select 1 = 1;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------+
| 1 | SIMPLE | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | No tables used |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------+
1 row in set, 1 warning (0.00 sec)
- Impossible WHERE
查询语句的
WHERE子句永远为FALSE时将会提示该额外信息
mysql> explain select * from s1 where 1 = 2;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+------------------+
| 1 | SIMPLE | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | Impossible WHERE |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+------------------+
1 row in set, 1 warning (0.00 sec)
- No matching min/max row
当查询列表处有 MIN 或者 MAX 聚集函数,但是并没有符合 WHERE 子句中的搜索条件的记录时,将会提示该额外信息
mysql> explain select max(id) from s1 where id = '99999999';
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra
|
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------------------+
| 1 | SIMPLE | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | No matching min/max row |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------------------+
1 row in set, 1 warning (0.00 sec)
- Using index 当我们的查询列表以及搜索条件中只包含属于某个索引的列,也就是在可以使用索引覆盖的情况下,在 Extra 列将会提示该额外信息。比方说下边这个查询中只需要用到 idx_key1 而不需要回表操作:
mysql> explain select key1 from s1 where key1 = 'a';
+----+-------------+-------+------------+------+---------------+----------+---------+-------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+----------+---------+-------+------+----------+-------------+
| 1 | SIMPLE | s1 | NULL | ref | idx_key1 | idx_key1 | 303 | const | 1 | 100.00 | Using index |
+----+-------------+-------+------------+------+---------------+----------+---------+-------+------+----------+-------------+
1 row in set, 1 warning (0.72 sec)
- Using index condition 有些搜索条件中虽然出现了索引列,但却不能使用到索引,比如下边这个查询:
SELECT * FROM s1 WHERE key1 > 'z' AND key1 LIKE '%a';
其中的 key1 > 'z' 可以使用到索引,但是 key1 LIKE '%a' 却无法使用到索引,在以前版本的 MySQL 中,
是按照下边步骤来执行这个查询的:
- 先根据 key1 > 'z' 这个条件,从二级索引 idx_key1 中获取到对应的二级索引记录。
- 根据上一步骤得到的二级索引记录中的主键值进行回表,找到完整的用户记录再检测该记录是否符合 key1 LIKE '%a' 这个条件,将符合条件的记录加入到最后的结果集。
但是虽然 key1 LIKE '%a' 不能组成范围区间参与 range 访问方法的执行,但这个条件毕竟只涉及到了 key1 列,所以设计 MySQL 的大叔把上边的步骤改进了一下:
- 先根据 key1 > 'z' 这个条件,定位到二级索引 idx_key1 中对应的二级索引记录。
- 对于指定的二级索引记录,先不着急回表,而是先检测一下该记录是否满足 key1 LIKE '%a' 这个条件,如果这个条件不满足,则该二级索引记录压根儿就没必要回表。
- 对于满足 key1 LIKE '%a' 这个条件的二级索引记录执行回表操作。
我们说回表操作其实是一个随机 IO ,比较耗时,所以上述修改虽然只改进了一点点,但是可以省去好多回表操作的成本。设计 MySQL 的大叔们把他们的这个改进称之为 索引条件下推 (英文名: Index Condition Pushdown )。如果在查询语句的执行过程中将要使用 索引条件下推 这个特性,在 Extra 列中将会显示 Using index condition ,比如这样:
mysql> show index from s1;
+-------+------------+--------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+-------+------------+--------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| s1 | 0 | PRIMARY | 1 | id | A | 9636 | NULL | NULL | | BTREE | | |
| s1 | 0 | idx_key2 | 1 | key2 | A | 9636 | NULL | NULL | YES | BTREE | | |
| s1 | 1 | idx_key1 | 1 | key1 | A | 9636 | NULL | NULL | YES | BTREE | | |
| s1 | 1 | idx_key3 | 1 | key3 | A | 9636 | NULL | NULL | YES | BTREE | | |
| s1 | 1 | idx_key_part | 1 | key_part1 | A | 9256 | NULL | NULL | YES | BTREE | | |
| s1 | 1 | idx_key_part | 2 | key_part2 | A | 9636 | NULL | NULL | YES | BTREE | | |
| s1 | 1 | idx_key_part | 3 | key_part3 | A | 9636 | NULL | NULL | YES | BTREE | | |
+-------+------------+--------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
7 rows in set (0.04 sec)
mysql> explain select * from s1 where key1 > 'd' and key1 like '%f';
+----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | s1 | NULL | range | idx_key1 | idx_key1 | 303 | NULL | 1636 | 100.00 | Using index condition |
+----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)
mysql> explain select * from s1 where key_part1 > 'f' and key_part3 like '%d';
+----+-------------+-------+------------+-------+---------------+--------------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+--------------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | s1 | NULL | range | idx_key_part | idx_key_part | 303 | NULL | 531 | 11.11 | Using index condition |
+----+-------------+-------+------------+-------+---------------+--------------+---------+------+------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)
- Using where 当我们使用全表扫描来执行对某个表的查询,并且该语句的 WHERE 子句中有针对该表的搜索条件时,在Extra 列中会提示上述额外信息。
mysql> explain select * from s1 where common_field = 'a';
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | s1 | NULL | ALL | NULL | NULL | NULL | NULL | 9636 | 10.00 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.40 sec)
当使用索引访问来执行对某个表的查询,并且该语句的 WHERE 子句中有除了该索引包含的列之外的其他搜索条件时,在 Extra 列中也会提示上述额外信息。server层进行过滤 https://mariadb.com/kb/en/explain/#explain-extended (opens new window)
Using where意味着对于使用该索引实际返回的每一行,server将需要验证这些行是否与WHERE子句的其余部分匹配 https://stackoverflow.com/questions/42186460/using-where-during-explain-for-mysql-query?noredirect=1&lq=1 (opens new window)
mysql> explain select * from s1 where key1 = 'a' and common_field = 'b';
+----+-------------+-------+------------+------+---------------+----------+---------+-------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+----------+---------+-------+------+----------+-------------+
| 1 | SIMPLE | s1 | NULL | ref | idx_key1 | idx_key1 | 303 | const | 1 | 10.00 | Using where |
+----+-------------+-------+------------+------+---------------+----------+---------+-------+------+----------+-------------+
1 row in set, 1 warning (0.19 sec)
- Using join buffer (Block Nested Loop) 在连接查询执行过程中,当被驱动表不能有效的利用索引加快访问速度, MySQL 一般会为其分配一块名叫 join buffer 的内存块来加快查询速度,也就是我们所讲的 基于块的嵌套循环算法
mysql> explain select * from s1 inner join s2 where s1.common_field = s2.common_field;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
| 1 | SIMPLE | s2 | NULL | ALL | NULL | NULL | NULL | NULL | 8646 | 100.00 | NULL |
| 1 | SIMPLE | s1 | NULL | ALL | NULL | NULL | NULL | NULL | 9636 | 10.00 | Using where; Using join buffer (Block Nested Loop) |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
2 rows in set, 1 warning (0.05 sec)
Using join buffer (Block Nested Loop) :这是因为对表 s2 的访问不能有效利用索引,只好退而求其次,使用 join buffer 来减少对 s2 表的访问次数,从而提高性能。
Using where :可以看到查询语句中有一个 s1.common_field = s2.common_field 条件,因为 s1 是驱动表, s2 是被驱动表,所以在访问 s2 表时, s1.common_field 的值已经确定下来了,所以实际上查 询 s2 表的条件就是 s2.common_field = 一个常数 ,所以提示了 Using where 额外信息。
Not exists
当我们使用外连接时,如果 WHERE 子句中包含要求被驱动表的某个列等于 NULL 值的搜索条件,而且那个列又是不允许存储 NULL 值的,那么在该表的执行计划的 Extra 列就会提示 Not exists 额外信息
mysql> explain select * from s1 left join s2 on s1.key1 = s2.key1 where s2.id is null;
+----+-------------+-------+------------+------+---------------+----------+---------+-----------------+------+----------+-------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+----------+---------+-----------------+------+----------+-------------------------+
| 1 | SIMPLE | s1 | NULL | ALL | NULL | NULL | NULL | NULL | 9636 | 100.00 | NULL |
| 1 | SIMPLE | s2 | NULL | ref | idx_key1 | idx_key1 | 303 | test_db.s1.key1 | 1 | 10.00 | Using where; Not exists |
+----+-------------+-------+------------+------+---------------+----------+---------+-----------------+------+----------+-------------------------+
2 rows in set, 1 warning (0.00 sec)
- Using intersect(...) 、 Using union(...) 和 Using sort_union(...) 如果执行计划的 Extra 列出现了 Using intersect(...) 提示,说明准备使用 Intersect 索引合并的方式执行查询,括号中的 ... 表示需要进行索引合并的索引名称;如果出现了 Using union(...) 提示,说明准备 使用 Union 索引合并的方式执行查询;出现了 Using sort_union(...) 提示,说明准备使用 Sort-Union 索 引合并的方式执行查询。https://dev.mysql.com/doc/refman/5.7/en/index-merge-optimization.html (opens new window)
- Zero limit 当我们的 LIMIT 子句的参数为 0 时,表示压根儿不打算从表中读出任何记录,将会提示该额外信息
mysql> explain select * from s1 limit 0;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+------------+
| 1 | SIMPLE | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | Zero limit |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+------------+
1 row in set, 1 warning (0.03 sec)
- Using filesort
有一些情况下对结果集中的记录进行排序是可以使用到索引的
mysql> explain select * from s1 order by key1 limit 10;
+----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+-------+
| 1 | SIMPLE | s1 | NULL | index | NULL | idx_key1 | 303 | NULL | 10 | 100.00 | NULL |
+----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+-------+
1 row in set, 1 warning (0.03 sec)
这个查询语句可以利用 idx_key1 索引直接取出 key1 列的10条记录,然后再进行回表操作就好了。但是很多情况下排序操作无法使用到索引,只能在内存中(记录较少的时候)或者磁盘中(记录较多的时候)进行 排序,设计 MySQL 的大叔把这种在内存中或者磁盘上进行排序的方式统称为文件排序(英文名:filesort )。如果某个查询需要使用文件排序的方式执行查询,就会在执行计划的 Extra 列中显示 Using filesort 提示
mysql> explain select * from s1 order by common_field limit 10;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------+
| 1 | SIMPLE | s1 | NULL | ALL | NULL | NULL | NULL | NULL | 9636 | 100.00 | Using filesort |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------+
1 row in set, 1 warning (0.00 sec)
需要注意的是,如果查询中需要使用 filesort 的方式进行排序的记录非常多,那么这个过程是很耗费性能的,我们最好想办法将使用 文件排序 的执行方式改为使用索引进行排序。
- Using temporary
在许多查询的执行过程中, MySQL 可能会借助临时表来完成一些功能,比如去重、排序之类的,比如我们在执行许多包含 DISTINCT 、 GROUP BY 、 UNION 等子句的查询过程中,如果不能有效利用索引来完成查询, MySQL 很有可能寻求通过建立内部的临时表来执行查询。如果查询中使用到了内部的临时表,在执行计划的 Extra 列将会显示 Using temporary 提示
mysql> explain select distinct common_field from s1;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-----------------+
| 1 | SIMPLE | s1 | NULL | ALL | NULL | NULL | NULL | NULL | 9636 | 100.00 | Using temporary |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-----------------+
1 row in set, 1 warning (0.11 sec)
mysql> explain select common_field, count(*) from s1 group by common_field;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+---------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+---------------------------------+
| 1 | SIMPLE | s1 | NULL | ALL | NULL | NULL | NULL | NULL | 9636 | 100.00 | Using temporary; Using filesort |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+---------------------------------+
1 row in set, 1 warning (0.06 sec)
# 默认 order by 分组字段
mysql> explain select common_field, count(*) from s1 group by common_field order by common_field;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+---------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+---------------------------------+
| 1 | SIMPLE | s1 | NULL | ALL | NULL | NULL | NULL | NULL | 9636 | 100.00 | Using temporary; Using filesort |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+---------------------------------+
1 row in set, 1 warning (0.00 sec)
# 不想进行排序 order by null
mysql> explain select common_field, count(*) from s1 group by common_field order by null;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-----------------+
| 1 | SIMPLE | s1 | NULL | ALL | NULL | NULL | NULL | NULL | 9636 | 100.00 | Using temporary |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-----------------+
1 row in set, 1 warning (0.09 sec)
# Json格式的执行计划
查看某个执行计划花费的成本
- 在EXPLAIN 单词和真正的查询语句中间加上
FORMAT=JSON。
mysql> explain format = json select * from s1 inner join s2 on s1.key1 = s2.key2 where s1.common_field = 'a'\G
*************************** 1. row ***************************
EXPLAIN: {
"query_block": {
# 整个查询语句只有1个SELECT关键字,该关键字对应的id号为1
"select_id": 1,
"cost_info": {
# 整个查询的执行成本预计为3244.52
"query_cost": "3244.52"
},
# 几个表之间采用嵌套循环连接算法执行
"nested_loop": [
{
"table": {
# s1表是驱动表
"table_name": "s1",
# 访问方法为ALL,意味着使用全表扫描访问
"access_type": "ALL",
# 可能使用的索引
"possible_keys": [
"idx_key1"
],
# 查询一次s1表大致需要扫描9636条记录
"rows_examined_per_scan": 9636,
# 驱动表s1的扇出是963
"rows_produced_per_join": 963,
# condition filtering代表的百分比
"filtered": "10.00",
"cost_info": {
"read_cost": "1895.48",
"eval_cost": "192.72",
# 单次查询s1表总共的成本
"prefix_cost": "2088.20",
# 读取的数据量
"data_read_per_join": "1M"
},
# 执行查询中涉及到的列
"used_columns": [
"id",
"key1",
"key2",
"key3",
"key_part1",
"key_part2",
"key_part3",
"common_field"
],
# 对s1表访问时针对单表查询的条件
"attached_condition": "((`test_db`.`s1`.`common_field` = 'a') and (`test_db`.`s1`.`key1` is not null))"
}
},
{
"table": {
# s2表是被驱动表
"table_name": "s2",
# 访问方法为ref,意味着使用索引等值匹配的方式访问
"access_type": "ref",
# 可能使用的索引
"possible_keys": [
"idx_key2"
],
# 实际使用的索引
"key": "idx_key2",
# 使用到的索引列
"used_key_parts": [
"key2"
],
# 索引长度 byte
"key_length": "5",
# 与key2列进行等值匹配的对象
"ref": [
"test_db.s1.key1"
],
# 查询一次s2表大致需要扫描1条记录
"rows_examined_per_scan": 1,
# 被驱动表s2的扇出是968(由于后边没有多余的表
进行连接,所以这个值也没啥用)
"rows_produced_per_join": 963,
# condition filtering代表的百分比
"filtered": "100.00",
# s2表使用索引进行查询的搜索条件
"index_condition": "(`test_db`.`s1`.`key1` = `test_db`.`s2`.`key2`)",
"cost_info": {
"read_cost": "963.60",
"eval_cost": "192.72",
# 单次查询s1、多次查询s2表总共的成本
"prefix_cost": "3244.52",
# 读取的数据量
"data_read_per_join": "1M"
},
# 执行查询中涉及到的列
"used_columns": [
"id",
"key1",
"key2",
"key3",
"key_part1",
"key_part2",
"key_part3",
"common_field"
]
}
}
]
}
}
1 row in set, 2 warnings (0.00 sec)
先看 s1 表的 "cost_info" 部分:
"cost_info": {
"read_cost": "1895.48",
"eval_cost": "192.72",
"prefix_cost": "2088.20",
"data_read_per_join": "1M"
}
- read_cost 是由下边这两部分组成的:
- IO 成本
- 检测 rows × (1 - filter) 条记录的 CPU 成本 rows和filter都是我们前边介绍执行计划的输出列,在JSON格式的执行计划中,rows相当于rows_examined_per_scan,filtered名称不变。
- eval_cost 是这样计算的:
检测 rows × filter 条记录的成本。
- prefix_cost 就是单独查询 s1 表的成本,也就是:
read_cost + eval_cost
- data_read_per_join 表示在此次查询中需要读取的数据量
对于 s2 表的 "cost_info" 部分是这样的:
"cost_info": {
"read_cost": "963.60",
"eval_cost": "192.72",
"prefix_cost": "3244.52",
"data_read_per_join": "1M"
}
由于 s2 表是被驱动表,所以可能被读取多次,这里的 read_cost 和 eval_cost 是访问多次 s2 表后累加起来的值,大家主要关注里边儿的 prefix_cost 的值代表的是整个连接查询预计的成本,也就是单次查询 s1 表和多次 查询 s2 表后的成本的和,也就是: 963.60 + 192.72 + 2088.20 = 3244.52
# Extented EXPLAIN
在我们使用 EXPLAIN 语句查看了某个查询的执行计划后,紧接着 还可以使用 SHOW WARNINGS 语句查看与这个查询的执行计划有关的一些扩展信息
mysql> explain select s1.key1, s2.key1 from s1 left join s2 on s1.key1 = s2.key1 where s2.common_field is not null;
+----+-------------+-------+------------+------+---------------+----------+---------+-----------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+----------+---------+-----------------+------+----------+-------------+
| 1 | SIMPLE | s2 | NULL | ALL | idx_key1 | NULL | NULL | NULL | 8646 | 90.00 | Using where |
| 1 | SIMPLE | s1 | NULL | ref | idx_key1 | idx_key1 | 303 | test_db.s2.key1 | 1 | 100.00 | Using index |
+----+-------------+-------+------------+------+---------------+----------+---------+-----------------+------+----------+-------------+
2 rows in set, 1 warning (0.02 sec)
mysql> show warnings\G
*************************** 1. row ***************************
Level: Note
Code: 1003
Message: /* select#1 */ select `test_db`.`s1`.`key1` AS `key1`,`test_db`.`s2`.`key1` AS `key1` from `test_db`.`s1` join `test_db`.`s2` where ((`test_db`.`s1`.`key1` =
`test_db`.`s2`.`key1`) and (`test_db`.`s2`.`common_field` is not null))
1 row in set (0.00 sec)
- 当 Code 值为 1003 时, Message 字段展示的信息_类似于_查询优化器将我们的查询语句重写后的语句
- Message 字段展示的信息_类似于_查询优化器将我们的查询语句重写后的语句,并不是等价于
# optimizer trace
在 MySQL 5.6 以及之后的版本中,设计 MySQL 的大叔贴心的为这部分小伙伴提出了一个 optimizer trace 的功能,这个功能可以让我们方便的查看优化器生成执行计划的整个过程,这个功能的开启与关闭由系统变量 optimizer_trace 决定
mysql> show variables like 'optimizer_trace';
+-----------------+--------------------------+
| Variable_name | Value |
+-----------------+--------------------------+
| optimizer_trace | enabled=off,one_line=off |
+-----------------+--------------------------+
1 row in set, 1 warning (0.01 sec)
mysql> set optimizer_trace ='enabled=on';
Query OK, 0 rows affected (0.04 sec)
然后我们就可以输入我们想要查看优化过程的查询语句,当该查询语句执行完成后,就可以到 information_schema 数据库下的 OPTIMIZER_TRACE 表中查看完整的优化过程。这个 OPTIMIZER_TRACE 表有4个列,分别是:
- QUERY :表示我们的查询语句。
- TRACE :表示优化过程的JSON格式文本。
- MISSING_BYTES_BEYOND_MAX_MEM_SIZE :由于优化过程可能会输出很多,如果超过某个限制时,多余的文本将不会被显示,这个字段展示了被忽略的文本字节数。
- INSUFFICIENT_PRIVILEGES :表示是否没有权限查看优化过程,默认值是0,只有某些特殊情况下才会是1 ,我们暂时不关心这个字段的值。
完整的使用 optimizer trace 功能的步骤总结如下:
# 1. 打开optimizer trace功能 (默认情况下它是关闭的):
SET optimizer_trace="enabled=on";
# 2. 这里输入你自己的查询语句
SELECT ...;
# 3. 从OPTIMIZER_TRACE表中查看上一个查询的优化过程
SELECT * FROM information_schema.OPTIMIZER_TRACE;
# 4. 可能你还要观察其他语句执行的优化过程,重复上边的第2、3步
...
# 5. 当你停止查看语句的优化过程时,把optimizer trace功能关闭
SET optimizer_trace="enabled=off";
现在我们有一个搜索条件比较多的查询语句
mysql> explain select * from s1 where
-> key1 > 'z' and
-> key2 < 1000000 and
-> key3 in ('a','b','c') and
-> common_field = 'abc';
+----+-------------+-------+------------+-------+----------------------------+----------+---------+------+------+----------+------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+----------------------------+----------+---------+------+------+----------+------------------------------------+
| 1 | SIMPLE | s1 | NULL | range | idx_key2,idx_key1,idx_key3 | idx_key2 | 5 | NULL | 1 | 5.00 | Using index condition; Using where |
+----+-------------+-------+------------+-------+----------------------------+----------+---------+------+------+----------+------------------------------------+
1 row in set, 1 warning (0.29 sec)
可以看到该查询可能使用到的索引有3个,那么为什么优化器最终选择了 idx_key2 而不选择其他的索引或者直接全表扫描呢?这时候就可以通过 otpimzer trace 功能来查看优化器的具体工作过程:
SET optimizer_trace="enabled=off";
SET optimizer_trace="enabled=on";
SELECT * FROM s1 WHERE
key1 > 'z' AND
key2 < 1000000 AND
key3 IN ('a', 'b', 'c') AND
common_field = 'abc';
SELECT * FROM information_schema.OPTIMIZER_TRACE\G
mysql> select * from information_schema.optimizer_trace\G
*************************** 1. row ***************************
# 要分析的查询语句
QUERY: SELECT * FROM s1 WHERE
key1 > 'z' AND
key2 < 1000000 AND
key3 IN ('a', 'b', 'c') AND
common_field = 'abc'
# 优化的具体过程
TRACE: {
"steps": [
{
# prepare阶段
"join_preparation": {
"select#": 1,
"steps": [
{
"IN_uses_bisection": true
},
{
"expanded_query": "/* select#1 */ select `s1`.`id` AS `id`,`s1`.`key1` AS `key1`,`s1`.`key2` AS `key2`,`s1`.`key3` AS `key3`,`s1`.`key_part1` AS `key_part1
`,`s1`.`key_part2` AS `key_part2`,`s1`.`key_part3` AS `key_part3`,`s1`.`common_field` AS `common_field` from `s1` where ((`s1`.`key1` > 'z') and (`s1`.`key2` < 1000000
) and (`s1`.`key3` in ('a','b','c')) and (`s1`.`common_field` = 'abc'))"
}
]
}
},
{
# optimize阶段
"join_optimization": {
"select#": 1,
"steps": [
{
# 处理搜索条件
"condition_processing": {
"condition": "WHERE",
# 原始搜索条件
"original_condition": "((`s1`.`key1` > 'z') and (`s1`.`key2` < 1000000) and (`s1`.`key3` in ('a','b','c')) and (`s1`.`common_field` = 'abc'))",
"steps": [
{
# 等值传递转换
"transformation": "equality_propagation",
"resulting_condition": "((`s1`.`key1` > 'z') and (`s1`.`key2` < 1000000) and (`s1`.`key3` in ('a','b','c')) and (`s1`.`common_field` = 'abc'))"
},
{
# 常量传递替换
"transformation": "constant_propagation",
"resulting_condition": "((`s1`.`key1` > 'z') and (`s1`.`key2` < 1000000) and (`s1`.`key3` in ('a','b','c')) and (`s1`.`common_field` = 'abc'))"
},
{
# 去除没用的条件
"transformation": "trivial_condition_removal",
"resulting_condition": "((`s1`.`key1` > 'z') and (`s1`.`key2` < 1000000) and (`s1`.`key3` in ('a','b','c')) and (`s1`.`common_field` = 'abc'))"
}
]
}
},
{
# 替换虚拟生成列
"substitute_generated_columns": {
}
},
{
# 表的依赖信息
"table_dependencies": [
{
"table": "`s1`",
"row_may_be_null": false,
"map_bit": 0,
"depends_on_map_bits": [
]
}
]
},
{
"ref_optimizer_key_uses": [
]
},
{
# 预估不同单表访问方法的访问成本
"rows_estimation": [
{
"table": "`s1`",
"range_analysis": {
# 全表扫描的行数及成本
"table_scan": {
"rows": 9636,
"cost": 2090.3
},
"potential_range_indexes": [
{
# 主键不可用
"index": "PRIMARY",
"usable": false,
"cause": "not_applicable"
},
{
# idx_key2可能被使用
"index": "idx_key2",
"usable": true,
"key_parts": [
"key2"
]
},
{
# idx_key1可能被使用
"index": "idx_key1",
"usable": true,
"key_parts": [
"key1",
"id"
]
},
{
# idx_key3可能被使用
"index": "idx_key3",
"usable": true,
"key_parts": [
"key3",
"id"
]
},
{
# idx_key_part不可用
"index": "idx_key_part",
"usable": false,
"cause": "not_applicable"
}
],
"setup_range_conditions": [
],
"group_index_range": {
"chosen": false,
"cause": "not_group_by_or_distinct"
},
# 分析各种可能使用的索引的成本
"analyzing_range_alternatives": {
"range_scan_alternatives": [
{
# 使用idx_key2的成本分析
"index": "idx_key2",
# 使用idx_key2的范围成本
"ranges": [
"NULL < key2 < 1000000"
],
# 是否使用index dive
"index_dives_for_eq_ranges": true,
# 使用该索引获取的记录是否按照主键排序
"rowid_ordered": false,
# 是否使用 mrr
"using_mrr": false,
# 是否使用索引覆盖访问
"index_only": false,
# 使用该索引获取的记录条数
"rows": 1,
# 使用该索引的成本
"cost": 2.21,
# 是否选择该索引
"chosen": true
},
{
# idx_key1的成本分析
"index": "idx_key1",
# 使用idx_key1的范围区间
"ranges": [
"z < key1"
],
"index_dives_for_eq_ranges": true,
"rowid_ordered": false,
"using_mrr": false,
"index_only": false,
"rows": 1,
"cost": 2.21,
"chosen": false,
"cause": "cost"
},
{
# 使用idx_key3的成本分析
"index": "idx_key3",
# 使用idx_key3的范围区间
"ranges": [
"a <= key3 <= a",
"b <= key3 <= b",
"c <= key3 <= c"
],
"index_dives_for_eq_ranges": true,
"rowid_ordered": false,
"using_mrr": false,
"index_only": false,
"rows": 3,
"cost": 6.61,
"chosen": false,
"cause": "cost"
}
],
# 分析使用索引合并的成本
"analyzing_roworder_intersect": {
"usable": false,
"cause": "too_few_roworder_scans"
}
},
# 对于上述单表查询s1最优的访问方法
"chosen_range_access_summary": {
"range_access_plan": {
"type": "range_scan",
"index": "idx_key2",
"rows": 1,
"ranges": [
"NULL < key2 < 1000000"
]
},
"rows_for_plan": 1,
"cost_for_plan": 2.21,
"chosen": true
}
}
}
]
},
{
# 分析各种可能的执行计划
#(对多表查询这可能有很多种不同的方案,单表查询的方案上边已经分析过了,直接选 取idx_key2就好)
"considered_execution_plans": [
{
"plan_prefix": [
],
"table": "`s1`",
"best_access_path": {
"considered_access_paths": [
{
"rows_to_scan": 1,
"access_type": "range",
"range_details": {
"used_index": "idx_key2"
},
"resulting_rows": 1,
"cost": 2.41,
"chosen": true
}
]
},
"condition_filtering_pct": 100,
"rows_for_plan": 1,
"cost_for_plan": 2.41,
"chosen": true
}
]
},
{
# 尝试给查询添加一些其他的查询条件
"attaching_conditions_to_tables": {
"original_condition": "((`s1`.`key1` > 'z') and (`s1`.`key2` < 1000000) and (`s1`.`key3` in ('a','b','c')) and (`s1`.`common_field` = 'abc'))",
"attached_conditions_computation": [
],
"attached_conditions_summary": [
{
"table": "`s1`",
"attached": "((`s1`.`key1` > 'z') and (`s1`.`key2` < 1000000) and (`s1`.`key3` in ('a','b','c')) and (`s1`.`common_field` = 'abc'))"
}
]
}
},
{
# 再稍稍的改进一下执行计划
"refine_plan": [
{
"table": "`s1`",
"pushed_index_condition": "(`s1`.`key2` < 1000000)",
"table_condition_attached": "((`s1`.`key1` > 'z') and (`s1`.`key3` in ('a','b','c')) and (`s1`.`common_field` = 'abc'))"
}
]
}
]
}
},
{
# execute阶段
"join_execution": {
"select#": 1,
"steps": [
]
}
}
]
}
# 因优化过程文本太多而丢弃的文本字节大小,值为0时表示并没有丢弃
MISSING_BYTES_BEYOND_MAX_MEM_SIZE: 0
# 权限字段
INSUFFICIENT_PRIVILEGES: 0
1 row in set (0.09 sec)
优化过程大 致分为了三个阶段:
- prepare 阶段
- optimize 阶段
- execute 阶段
我们所说的基于成本的优化主要集中在 optimize 阶段
- 对于单表查询来说,我们主要关注 optimize 阶段的 "rows_estimation" 这个过程,这个过程深入分析了对单表查询的各种执行方案的成本;
- 对于多表连接查询来 说,我们更多需要关注 "considered_execution_plans" 这个过程,这个过程里会写明各种不同的连接方式所对 应的成本。
反正优化器最终会选择成本最低的那种方案来作为最终的执行计划,也就是我们使用 EXPLAIN 语句所 展现出的那种方案。
# BufferPool
# 概述
设计 InnoDB 的大叔为了缓存磁盘中的页,在 MySQL 服务器启动的时候就向操作系统申请了一片连续的内存,他们给这片内存起了个名,叫做 Buffer Pool (中文名是 缓冲池 )。默认情况下 Buffer Pool 只有 128M 大小。当然如果你嫌弃这个 128M 太大或者太小,可以在启动服务器的时候配置 innodb_buffer_pool_size 参数的值,它表示 Buffer Pool 的大小,就像这样:
[server]
innodb_buffer_pool_size = 268435456
其中, 268435456 的单位是字节,也就是我指定 Buffer Pool 的大小为 256M 。需要注意的是, Buffer Pool 也 不能太小,最小值为 5M (当小于该值时会自动设置成 5M )。
# 内部组成
Buffer Pool 中默认的缓存页大小和在磁盘上默认的页大小是一样的,都是 16KB 。为了更好的管理这些在 Buffer Pool 中的缓存页,设计 InnoDB 的大叔为每一个缓存页都创建了一些所谓的 控制信息 ,这些控制信息包括该页所属的表空间编号、页号、缓存页在 Buffer Pool 中的地址、链表节点信息、一些锁信息以及 LSN 信息,当然还有一些别的控制信息
每个缓存页对应的控制信息占用的内存大小是相同的,我们就把每个页对应的控制信息占用的一块内存称为一个 控制块,控制块和缓存页是一一对应的,它们都被存放到 Buffer Pool 中,其中控制块被存放到 Buffer Pool的前边,缓存页被存放到 Buffer Pool 后边
 每一个控制块都对应一个缓存页,那在分配 足够多的控制块和缓存页后,可能剩余的那点儿空间不够一对控制块和缓存页的大小,这个用不到的内存空间就被称为 碎片 了。
每一个控制块都对应一个缓存页,那在分配 足够多的控制块和缓存页后,可能剩余的那点儿空间不够一对控制块和缓存页的大小,这个用不到的内存空间就被称为 碎片 了。
小贴士:
每个控制块大约占用缓存页大小的5%,在MySQL5.7.21这个版本中,每个控制块占用的大小是808字节。 而我们设置的innodb_buffer_pool_size并不包含这部分控制块占用的内存空间大小,也就是说InnoDB在为Buffer Pool向操作系统申请连续的内存空间时,这片连续的内存空间一般会比innodb_buffer_poo l_size的值大5%左右。
# free链表
在某个地方记录一下Buffer Pool中哪些缓存页是可用的,把所有空闲的缓存页对应的控制块作为一个节 点放到一个链表中,这个链表也可以被称作 free链表 (或者说空闲链表)
 我们为了管理好这个 free链表 ,特意为这个链表定义了一个 基节点
我们为了管理好这个 free链表 ,特意为这个链表定义了一个 基节点
小贴士:
链表基节点占用的内存空间并不大,在MySQL5.7.21这个版本里,每个基节点只占用40字节大小。后边我们即将介绍许多不同的链表,它们的基节点和free链表的基节点的内存分配方式是一样一样的,都是 单独申请的一块40字节大小的内存空间,并不包含在为Buffer Pool申请的一大片连续内存空间之内
# 缓存页的哈希
用 _表空间号 + 页号 _作为 key , 缓存页 作为 value 创建一个哈希表,在需要访问某个页的数据时,先从哈希表中根据表 空间号 + 页号 看看有没有对应的缓存页,如果有,直接使用该缓存页就好,如果没有,那就从 free链表 中选一个空闲的缓存页,然后把磁盘中对应的页加载到该缓存页的位置。
# flush链表
如果我们修改了 Buffer Pool 中某个缓存页的数据,那它就和磁盘上的页不一致了,这样的缓存页也被称为 脏页 (英文名: dirty page )。当然,最简单的做法就是每发生一次修改就立即同步到磁盘上对应的页上,但是频繁的往磁盘中写数据会严重的影响程序的性能(毕竟磁盘慢的像乌龟一样)。所以每次修改缓存页后,我们并不着急立即把修改同步到磁盘上,而是在未来的某个时间点进行同步
凡是修改过的缓存页对应的控制块都会作为一个节点加入到一个链表中,因为这个链表节点对应的缓存页都是需要被刷新到磁盘上的, 所以也叫 flush链表 。链表的构造和 free链表 差不多,假设某个时间点 Buffer Pool 中的脏页数量为 n

# LRU链表
当 Buffer Pool 中不再有空闲的缓存页时,就需要淘汰掉部分最近很少使用的缓存页。我们可以再创建一个链表,由于这个链表是为了按照_最近最少使用_的原则去淘汰缓存页 的,所以这个链表可以被称为 LRU链表 (LRU的英文全称:Least Recently Used)。当我们需要访问某个页时, 可以这样处理 LRU链表 :
- 如果该页不在 Buffer Pool 中,在把该页从磁盘加载到 Buffer Pool 中的缓存页时,就把该缓存页对应的控制块作为节点塞到链表的头部。
- 如果该页已经缓存在 Buffer Pool 中,则直接把该页对应的 控制块 移动到 LRU链表 的头部。
也就是说:只要我们使用到某个缓存页,就把该缓存页调整到 LRU链表 的头部,这样 LRU链表 尾部就是最近最少使用的缓存页。所以当 Buffer Pool 中的空闲缓存页使用完时,到 LRU链表 的尾部找些缓存页淘汰就OK啦
划分区域的LRU链表
- 情况一: InnoDB 提供了一个看起来比较贴心的服务—— 预读 (英文名: read ahead )。所谓 预读 ,就 是 InnoDB 认为执行当前的请求可能之后会读取某些页面,就预先把它们加载到 Buffer Pool 中。根据触发方式的不同, 预读 又可以细分为下边两种:
- 线性预读 设计 InnoDB 的大叔提供了一个系统变量 innodb_read_ahead_threshold ,如果顺序访问了某个区( extent )的页面超过这个系统变量的值,就会触发一次 异步 读取下一个区中全部的页面到 Buffer Pool 的请求。这个 innodb_read_ahead_threshold 系统变量的值默认是 56
- 随机预读 如果 Buffer Pool 中已经缓存了某个区的13个连续的页面,不论这些页面是不是顺序读取的,都会触发 一次 异步 读取本区中所有其的页面到 Buffer Pool 的请求。设计 InnoDB 的大叔同时提供了innodb_random_read_ahead 系统变量,它的默认值为 OFF
如果长时间未命中预读页,会逐渐向 LRU链表尾部移动,这就会导致处在 LRU链表 尾部的一些缓存页会很快的被淘汰掉,会大大降低缓存命中率。
- 情况二:有的小伙伴可能会写一些需要扫描全表的查询语句(比如没有建立合适的索引或者压根儿没有WHERE子句的查询) 扫描全表意味着什么?意味着将访问到该表所在的所有页!假设这个表中记录非常多的话,那该表会占用特别多的页 ,当需要访问这些页时,会把它们统统都加载到 Buffer Pool 中,Buffer Pool 中的所有页都被换了一次血,其他查询语句在执行时又得执行一次从磁盘加载到 Buffer Pool 的操作。而这种全表扫描的语句执行的频率也不高,每次执行都要把 Buffer Pool 中的缓存页换一次血,这 严重的影响到其他查询对 Buffer Pool 的使用,从而大大降低了缓存命中率。
总结一下上边说的可能降低 Buffer Pool 的两种情况:
- 加载到 Buffer Pool 中的页不一定被用到。
- 如果非常多的使用频率偏低的页被同时加载到 Buffer Pool 时,可能会把那些使用频率非常高的页从
Buffer Pool 中淘汰掉。
因为有这两种情况的存在,所以设计 InnoDB 的大叔把这个 LRU链表 按照一定比例分成两截,分别是:
- 一部分存储使用频率非常高的缓存页,所以这一部分链表也叫做 热数据 ,或者称 young区域 。
- 另一部分存储使用频率不是很高的缓存页,所以这一部分链表也叫做 冷数据 ,或者称 old区域 。
 按照某个比例将LRU链表分成两半的,不是某些节点固定是young区域的,某些节点固定是old区域的,随着程序的运行,某个节点所属的区域也可能发生变化。那这个划分成两截的比例怎么确定呢?对于 InnoDB 存储引擎来说,我们可以通过查看系统变量 innodb_old_blocks_pct 的值来确定 old 区域 在 LRU链表 中所占的比例,比方说这样:
按照某个比例将LRU链表分成两半的,不是某些节点固定是young区域的,某些节点固定是old区域的,随着程序的运行,某个节点所属的区域也可能发生变化。那这个划分成两截的比例怎么确定呢?对于 InnoDB 存储引擎来说,我们可以通过查看系统变量 innodb_old_blocks_pct 的值来确定 old 区域 在 LRU链表 中所占的比例,比方说这样:
mysql> show variables like 'innodb_old_blocks_pct';
+-----------------------+-------+
| Variable_name | Value |
+-----------------------+-------+
| innodb_old_blocks_pct | 37 |
+-----------------------+-------+
1 row in set, 1 warning (0.00 sec)
默认情况下, old 区域在 LRU链表 中所占的比例是 37% ,也就是说 old 区域大约占 LRU链 表 的 3/8 。修改配置文件
[server]
innodb_old_blocks_pct = 40
运行时修改(全局变量)
SET GLOBAL innodb_old_blocks_pct = 40;
- 当磁盘上的某个页面在初次加载到Buffer Pool中的某个缓存页时,该缓存页对应 的控制块会被放到old区域的头部
- 在对某个处在 old 区域的缓存页进行第一次访问时就在它对应的控制块中记录下来这个访问时间,如果后续的访问时间与第一次访问的时间在某个时间间隔内,那么该页面就不会被 从old区域移动到young区域的头部,否则将它移动到young区域的头部 可以通过 innodb_old_blocks_time 系统变量控制,默认1000,单位毫秒 如果第一次和最后一次访问该页面的时间间隔小于 1s (很明显在一次 全表扫描的过程中,多次访问一个页面中的时间不会超过 1s ),那么该页是不会被加入到 young 区域的
只有被访问的缓存页位于 young 区域的 1/4 的后边,才会被移动到 LRU链表 头部,这样就可以降低调整 LRU链表 的频率,从而提升性能(也就是说如果某个缓存页对应的节点在 young 区域的 1/4 中, 再次访问该缓存页时也不会将其移动到 LRU 链表头部)

# 刷新脏页到磁盘
- 从 LRU链表 的冷数据中刷新一部分页面到磁盘。
后台线程会定时从 LRU链表 尾部开始扫描一些页面,扫描的页面数量可以通过系统变量 innodb_lru_scan_depth 来指定,如果从里边儿发现脏页,会把它们刷新到磁盘。这种刷新页面的方式被称 之为 BUF_FLUSH_LRU 。
- 从 flush链表 中刷新一部分页面到磁盘。
后台线程也会定时从 flush链表 中刷新一部分页面到磁盘,刷新的速率取决于当时系统是不是很繁忙。这种刷新页面的方式被称之为 BUF_FLUSH_LIST 。
# 多个Buffer Pool实例
所以在 Buffer Pool 特别大的时候,我们可以把它们拆分成若 干个小的 Buffer Pool ,每个 Buffer Pool 都称为一个 实例 ,它们都是独立的
[server]
innodb_buffer_pool_instances = 2
 当innodb_buffer_pool_size的值小于1G的时候设置多个实例是无效的,InnoDB会默认把
innodb_buffer_pool_instances 的值修改为1。而我们鼓励在 Buffer Pool 大小或等于1G的时候设置多个 Buffer Pool 实例。
当innodb_buffer_pool_size的值小于1G的时候设置多个实例是无效的,InnoDB会默认把
innodb_buffer_pool_instances 的值修改为1。而我们鼓励在 Buffer Pool 大小或等于1G的时候设置多个 Buffer Pool 实例。
# innodb_buffer_pool_chunk_size
不再一次性为某个 Buffer Pool 实例向操作系统申请 一大片连续的内存空间,而是以一个所谓的 chunk 为单位向操作系统申请空间。也就是说一个 Buffer Pool 实例 其实是由若干个 chunk 组成的,一个 chunk 就代表一片连续的内存空间,里边儿包含了若干缓存页与其对应的控制块
 上图代表的 Buffer Pool 就是由2个实例组成的,每个实例中又包含2个 chunk 。
正是因为发明了这个 chunk 的概念,我们在服务器运行期间调整 Buffer Pool 的大小时就是以 chunk 为单位增加或者删除内存空间,而不需要重新向操作系统申请一片大的内存,然后进行缓存页的复制。这个所谓的 chunk 的大小是我们在启动操作 MySQL 服务器时通过 innodb_buffer_pool_chunk_size 启动参数指定的,它的默认值 是 134217728 ,也就是 128M 。不过需要注意的是,innodb_buffer_pool_chunk_size的值只能在服务器启动时指 定,在服务器运行过程中是不可以修改的。
上图代表的 Buffer Pool 就是由2个实例组成的,每个实例中又包含2个 chunk 。
正是因为发明了这个 chunk 的概念,我们在服务器运行期间调整 Buffer Pool 的大小时就是以 chunk 为单位增加或者删除内存空间,而不需要重新向操作系统申请一片大的内存,然后进行缓存页的复制。这个所谓的 chunk 的大小是我们在启动操作 MySQL 服务器时通过 innodb_buffer_pool_chunk_size 启动参数指定的,它的默认值 是 134217728 ,也就是 128M 。不过需要注意的是,innodb_buffer_pool_chunk_size的值只能在服务器启动时指 定,在服务器运行过程中是不可以修改的。
Buffer Pool 的缓存页除了用来缓存磁盘上的页面以外,还可以存储锁信息、自适应哈希索引等信息
# 查看Buffer Pool的状态信息
show engine innodb status\G
mysql> show engine innodb status\G
# 省略不相关
----------------------
BUFFER POOL AND MEMORY
----------------------
Total large memory allocated 137297920
Dictionary memory allocated 984094
Buffer pool size 8192
Free buffers 6708
Database pages 1474
Old database pages 529
Modified db pages 0
Pending reads 0
Pending writes: LRU 0, flush list 0, single page 0
Pages made young 446, not young 9732
0.00 youngs/s, 0.00 non-youngs/s
Pages read 962, created 520, written 2151
0.00 reads/s, 0.00 creates/s, 0.00 writes/s
No buffer pool page gets since the last printout
Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s
LRU len: 1474, unzip_LRU len: 0
I/O sum[0]:cur[0], unzip sum[0]:cur[0]
--------------
# 省略不相关
1 row in set (0.88 sec)
https://dev.mysql.com/doc/refman/5.7/en/innodb-buffer-pool.html (opens new window)
# 总结
- 磁盘太慢,用内存作为缓存很有必要。
- Buffer Pool 本质上是 InnoDB 向操作系统申请的一段连续的内存空间,可以通过
innodb_buffer_pool_size来调整它的大小。 - Buffer Pool 向操作系统申请的连续内存由控制块和缓存页组成,每个控制块和缓存页都是一一对应的,在填充足够多的控制块和缓存页的组合后, Buffer Pool 剩余的空间可能产生不够填充一组控制块和缓存页, 这部分空间不能被使用,也被称为 碎片 。
- InnoDB 使用了许多 链表 来管理 Buffer Pool 。
- free链表 中每一个节点都代表一个空闲的缓存页,在将磁盘中的页加载到 Buffer Pool 时,会从 free链表 中寻找空闲的缓存页。
- 为了快速定位某个页是否被加载到 Buffer Pool ,使用 表空间号 + 页号 作为 key ,缓存页作为 value ,建立哈希表。
- 在 Buffer Pool 中被修改的页称为 脏页 ,脏页并不是立即刷新,而是被加入到 flush链表 中,待之后的某个时刻同步到磁盘上。
- LRU链表 分为 young 和 old 两个区域,可以通过 innodb_old_blocks_pct 来调节 old 区域所占的比例。首次从磁盘上加载到 Buffer Pool 的页会被放到 old 区域的头部,在 innodb_old_blocks_time 间隔时间内访 问该页不会把它移动到 young 区域头部。在 Buffer Pool 没有可用的空闲缓存页时,会首先淘汰掉 old 区 域的一些页。
- 我们可以通过指定 innodb_buffer_pool_instances 来控制 Buffer Pool 实例的个数,每个 Buffer Pool 实例中都有各自独立的链表,互不干扰。
- 自 MySQL 5.7.5 版本之后,可以在服务器运行过程中调整 Buffer Pool 大小。每个 Buffer Pool 实例由若干个 chunk 组成,每个 chunk 的大小可以在服务器启动时通过启动参数调整。
- 可以用下边的命令查看 Buffer Pool 的状态信息:
SHOW ENGINE INNODB STATUS\G
# 事务
# ACID
- 原子性(Atomicity):一个事务(transaction)中的所有操作,或者全部完成,或者全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚 (opens new window)(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。即,事务不可分割、不可约简。[1] (opens new window)
- 一致性 (opens new window)(Consistency):在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设约束 (opens new window)、触发器 (opens new window)、级联回滚 (opens new window)等。[1] (opens new window)
- 事务隔离 (opens new window)(Isolation):数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括未提交读(Read uncommitted)、提交读(read committed)、可重复读(repeatable read)和串行化(Serializable)。[1] (opens new window)
- 持久性 (opens new window)(Durability):事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。[1] (opens new window)
# 事务语法
MyISAM不支持事务(可以用事务语法(不报错),但是不起作用),InnoDB支持事务
- 开启事务
begin; 或者 start transaction; start transaction;可以在后面接修饰符:
- READ ONLY :标识当前事务是一个只读事务,也就是属于该事务的数据库操作只能读取数据,而不能修改数据。
- READ WRITE (默认):标识当前事务是一个读写事务,也就是属于该事务的数据库操作既可以读取数据,也可 以修改数据。
- WITH CONSISTENT SNAPSHOT :启动一致性读
- 提交事务
COMMIT
- 中止事务
ROLLBACK
- 自动提交
mysql> show variables like 'autocommit';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| autocommit | ON |
+---------------+-------+
1 row in set, 1 warning (0.00 sec)
- 隐式提交
使用 commit 会提交事务,有些特殊语句也会隐式的提交事务
- 定义或修改数据库对象的数据定义语言(Data definition language,缩写为: DDL )。
所谓的数据库对象,指的就是 数据库 、 表 、 视图 、 存储过程 等等这些东西。当我们使用 CREATE 、 ALTER 、 DROP 等语句去修改这些所谓的数据库对象时,就会隐式的提交前边语句所属于的事务
- 隐式使用或修改 mysql 数据库中的表 当我们使用 ALTER USER 、 CREATE USER 、 DROP USER 、 GRANT 、 RENAME USER 、 REVOKE 、 SET PASSWORD 等语句时也会隐式的提交前边语句所属于的事务。
- 事务控制或关于锁定的语句
- 当我们在一个事务还没提交或者回滚时就又使用 START TRANSACTION 或者 BEGIN 语句开启了另一个事务时, 会隐式的提交上一个事务。
- 或者当前的 _autocommit _系统变量的值为 OFF ,我们手动把它调为 ON 时,也会隐式的提交前边语句所属的事务。
- 或者使用 LOCK TABLES 、 UNLOCK TABLES 等关于锁定的语句也会隐式的提交前边语句所属的事务
- 加载数据的语句 比如我们使用 LOAD DATA 语句来批量往数据库中导入数据时,也会隐式的提交前边语句所属的事务
- 关于 MySQL 复制的一些语句 使用 START SLAVE 、 STOP SLAVE 、 RESET SLAVE 、 CHANGE MASTER TO 等语句时也会隐式的提交前边语句所属的事务。
- 其它的一些语句 使用 ANALYZE TABLE 、 CACHE INDEX 、 CHECK TABLE 、 FLUSH 、 LOAD INDEX INTO CACHE 、 OPTIMIZE TABLE 、 REPAIR TABLE 、 RESET 等语句也会隐式的提交前边语句所属的事务。
- 保存点
在事务对应的数据库语句中打几个点,我们 在调用 ROLLBACK 语句时可以指定会滚到哪个点,而不是回到最初的原点
- 定义保存点
SAVEPOINT 保存点名称;
- 回滚到保存点
ROLLBACK [WORK] TO [SAVEPOINT] 保存点名称; - 删除保存点
RELEASE SAVEPOINT 保存点名称;
# redo log
# 介绍
https://dev.mysql.com/doc/refman/5.7/en/innodb-redo-log.html (opens new window) 重做日志是一种基于磁盘的数据结构,用于在崩溃恢复期间纠正由不完整事务写入的数据。 在正常操作期间,重做日志对由 SQL 语句或低级 API 调用产生的更改表数据的请求进行编码。 在意外关闭之前未完成更新数据文件的修改会在初始化期间和接受连接之前自动重播。
默认情况下,重做日志在磁盘上由名为 ib_logfile0 和 ib_logfile1 的两个文件物理表示。 MySQL 以循环方式写入重做日志文件。 重做日志中的数据根据受影响的记录进行编码; 这些数据统称为重做。 数据通过重做日志的过程由不断增加的 LSN 值表示。
好处:
- redo 日志占用的空间非常小
存储表空间ID、页号、偏移量以及需要更新的值所需的存储空间是很小的,并非一个完整的数据记录
- redo 日志是顺序写入磁盘的
在执行事务的过程中,每执行一条语句,就可能产生若干条 redo 日志,这些日志是按照产生的顺序写入磁 盘的,也就是使用顺序IO。
# redo日志格式
redo日志会把事务在执行过程中对数据库所做的所有修改都记录下来,在之后系统奔溃重启后可以把事务所做的任何修改都恢复出来

- type :该条 redo 日志的类型。
在 MySQL 5.7.21 这个版本中,设计 InnoDB 的大叔一共为 redo 日志设计了53种不同的类型
- space ID :表空间ID。
- page number :页号。
- data :该条 redo 日志的具体内容。
如果我们没有为某个表显式的定义主键,并且表中也没有定义 Unique 键,那么 InnoDB 会自动的为表添加一个称之为 row_id 的隐藏列作为主键。为这个 row_id 隐藏列赋值的方式如下:
- 服务器会在内存中维护一个全局变量,每当向某个包含隐藏的 row_id 列的表中插入一条记录时,就会把该
变量的值当作新记录的 row_id 列的值,并且把该变量自增1。
- 每当这个变量的值为256的倍数时,就会将该变量的值刷新到系统表空间的页号为 7 的页面中一个称之为
Max Row ID 的属性处。
- 当系统启动时,会将上边提到的 Max Row ID 属性加载到内存中,将该值加上256之后赋值给我们前边提到的全局变量(因为在上次关机时该全局变量的值可能大于 Max Row ID 属性值)。
# redo log block
设计 InnoDB 的大叔为了更好的进行系统奔溃恢复,他们把通过 mtr 生成的 redo 日志都放在了大小为 512字节 的页中。

https://github.com/hedengcheng/tech (opens new window)
# Mini-Transaction
设计MySQL的大叔把对底层页面的一次原子修改称作一个Mini Trasaction,即MTR。一个 MTR中包含若干条redo日志,在崩溃恢复时,要么全部恢复该MTR对应的redo日志,要么 全部不恢复。
Mini-TRansaction(MTR) – 定义
- mini-transaction不属于事务;InnoDB内部使用
- 对于InnoDB内所有page的访问(I/U/D/S),都需要mini-transaction支持
– 功能
- 访问page,对page加latch (只读访问:S latch;写访问:X latch)
- 修改page,写redo日志 (mtr本地缓存)
- page操作结束,提交mini-transaction (非事务提交)
- 将redo日志写入log buffer
- 将脏页加入Flush List链表
- 释放页面上的 S/X latch
– 总结
- mini-transaction,保证单page操作的原子性(读/写单一page)
- mini-transaction,保证多pages操作的原子性(索引SMO/记录链出,多pages访问的原子性)

# redo日志缓冲区
了解决磁盘速度过慢的问题而引入了 Buffer Pool 。同理,写入 redo 日 志时也不能直接直接写到磁盘上,实际上在服务器启动时就向操作系统申请了一大片称之为 redo log buffer 的 连续内存空间,翻译成中文就是 redo日志缓冲区 ,我们也可以简称为 log buffer 。
有后台线程不断的将redo log buffer中的redo日志刷新到硬盘的redo日志文件,也有后台 线程不断的将buffer pool里的脏页(只有加入到flush链表后的页面才能算作是脏页)刷新 到硬盘中的表空间中。设计InnoDB的大叔规定,在刷新一个脏页到硬盘时,该脏页对应的 redo日志应该被先刷新到redo日志文件。而redo日志是顺序刷新的,也就是说,在刷新redo log buffer的某条redo日志时,在它之前的redo日志也都应该被刷新到redo日志文 件。
# redo日志刷盘时机
mtr 运行过程中产生的一组 redo 日志在 mtr 结束时会被复制到 log buffer 中,在一些情况下它们会被刷新到磁盘里
- log buffer 空间不足时 log buffer 的大小是有限的(通过系统变量 innodb_log_buffer_size 指定),如果不停的往这个有限大小的 log buffer 里塞入日志,很快它就会被填满。设计 InnoDB 的大叔认为如果当前写入 log buffer 的 redo 日志量已经占满了 log buffer 总容量的大约一半左右,就需要把这些日志刷新到磁盘上。
- 事务提交时 之所以使用 redo 日志主要是因为它占用的空间少,还是顺序写,在事务提交时可以不把修改过的 Buffer Pool 页面刷新到磁盘,但是为了保证持久性,必须要把修改这些页面对应的 redo 日志刷新到磁盘。
- 后台线程不停的刷刷刷 后台有一个线程,大约每秒都会刷新一次 log buffer 中的 redo 日志到磁盘。
- 正常关闭服务器时
- 做所谓的 checkpoint 时
- 其他的一些情况...
# 日志文件组
数据目录(show variables like 'datadir';)下有两个默认的ib_logfile0 和 ib_logfile1 的文件, log buffer 中的日志默认情况下就是刷新到这两个磁盘文件中。
修改配置:
- innodb_log_group_home_dir 该参数指定了 redo 日志文件所在的目录,默认值就是当前的数据目录。
- innodb_log_file_size 该参数指定了每个 redo 日志文件的大小,在 MySQL 5.7.21 这个版本中的默认值为 48MB
- innodb_log_files_in_group
该参数指定 redo 日志文件的个数,默认值为2,最大值为100。
循环使用文件

log buffer 本质上是一片连续的内存空间,被划分成了若干个 512 字节大小的 block 。将log buffer中的redo日志刷新到磁盘的本质就是把block的镜像写入日志文件中,所以 redo 日志文件其实也是由若干个 512 字节大小的block组成。 redo 日志文件组中的每个文件大小都一样,格式也一样,都是由两部分组成:
- 前2048个字节,也就是前4个block是用来存储一些管理信息的。
- 从第2048字节往后是用来存储 log buffer 中的block镜像的。
所以我们前边所说的 循环 使用redo日志文件,其实是从每个日志文件的第2048个字节开始算,画个示意图就是 这样:

# Log Sequeue Number
设计 InnoDB 的大叔为记录已经写入的 redo 日志量,设计了一个称之为 Log Sequeue Number 的全局变量,翻译过来就是: 日志序列号 ,简称 lsn 。不过不像 人一出生的年龄是 0 岁,设计 InnoDB 的大叔规定初始的 lsn 值为 8704 (也就是一条 redo 日志也没写入时,lsn 的值为 8704 )。
每一组由mtr生成的redo日志都有一个唯一的LSN值与其对应,LSN值越小,说明 redo日志产生的越早
# flushed_to_disk_lsn
 我们前边说 lsn 是表示当前系统中写入的 redo 日志量,这包括了写到 log buffer 而没有刷新到磁盘的日志, 相应的,设计 InnoDB 的大叔提出了一个表示刷新到磁盘中的 redo 日志量的全局变量,称之为 flushed_to_disk_lsn 。系统第一次启动时,该变量的值和初始的 lsn 值是相同的,都是 8704 。随着系统的运 行, redo 日志被不断写入 log buffer ,但是并不会立即刷新到磁盘, lsn 的值就和 flushed_to_disk_lsn 的 值拉开了差距。
当有新的 redo 日志写入到 log buffer 时,首先 lsn 的值会增长,但 flushed_to_disk_lsn 不变, 随后随着不断有 log buffer 中的日志被刷新到磁盘上, flushed_to_disk_lsn 的值也跟着增长。如果两者的值 相同时,说明log buffer中的所有redo日志都已经刷新到磁盘中了
我们前边说 lsn 是表示当前系统中写入的 redo 日志量,这包括了写到 log buffer 而没有刷新到磁盘的日志, 相应的,设计 InnoDB 的大叔提出了一个表示刷新到磁盘中的 redo 日志量的全局变量,称之为 flushed_to_disk_lsn 。系统第一次启动时,该变量的值和初始的 lsn 值是相同的,都是 8704 。随着系统的运 行, redo 日志被不断写入 log buffer ,但是并不会立即刷新到磁盘, lsn 的值就和 flushed_to_disk_lsn 的 值拉开了差距。
当有新的 redo 日志写入到 log buffer 时,首先 lsn 的值会增长,但 flushed_to_disk_lsn 不变, 随后随着不断有 log buffer 中的日志被刷新到磁盘上, flushed_to_disk_lsn 的值也跟着增长。如果两者的值 相同时,说明log buffer中的所有redo日志都已经刷新到磁盘中了
# checkpoint
判断某些redo日志占用的磁盘空间是否可以覆盖的依据就是它对应的脏页是否已经刷新到磁盘里
在崩溃恢复 (opens new window)期间, InnoDB查找写入日志文件的检查点标签。它知道标签之前对数据库的所有修改都存在于数据库的磁盘映像中。然后InnoDB从检查点向前扫描日志文件,将记录的修改应用到数据库。

# undo log
# 介绍
https://dev.mysql.com/doc/refman/5.7/en/innodb-undo-logs.html (opens new window) 保存由活动事务 修改的数据副本的存储区域 。如果另一个事务需要查看原始数据(作为**_ 一致读取_**操作的一部分),则从该存储区域检索未修改的数据。
在 MySQL 5.6 和 MySQL 5.7 中,您可以使用 innodb_undo_tablespaces (opens new window) 变量 have undo logs 驻留在**undo tablespaces**中,可以将其放置在另一个存储设备上,例如SSD。在 MySQL 8.0 中,撤消日志驻留在 MySQL 初始化时创建的两个默认撤消表空间中,并且可以使用 CREATE UNDO TABLESPACE (opens new window)语法创建额外的撤消表空间。
撤消日志分为单独的部分, **插入撤消缓冲区**和 更新撤消缓冲区。
- 重做日志记录了事务的行为,可以很好地通过其对页进行“重做”操作。但是事务有时还需要进行回滚操作,这时就需要undo。因此在对数据库进行修改时,InnoDB存储引擎不但会产生redo,还会产生一定量的undo。这样如果用户执行的事务或语句由于某种原因失败了,又或者用户用一条ROLLBACK语句请求回滚,就可以利用这些undo信息将数据回滚到修改之前的样子。
- redo存放在重做日志文件中,与redo不同,undo存放在数据库内部的一个特殊段(segment)中,这个段称为undo段(undo segment)。undo段位于共享表空间内。可以通过py_innodb_page_info.py工具来查看当前共享表空间中undo的数量。
- undo是逻辑日志,因此只是将数据库逻辑地恢复到原来的样子。所有修改都被逻辑地取消了,但是数据结构和页本身在回滚之后可能大不相同。这是因为在多用户并发系统中,可能会有数十、数百甚至数千个并发事务。数据库的主要任务就是协调对数据记录的并发访问。比如,一个事务在修改当前一个页中某几条记录,同时还有别的事务在对同一个页中另几条记录进行修改。因此,不能将一个页回滚到事务开始的样子,因为这样会影响其他事务正在进行的工作。
- 除了回滚操作,undo的另一个作用是MVCC,即在InnoDB存储引擎中MVCC的实现是通过undo来完成。当用户读取一行记录时,若该记录已经被其他事务占用,当前事务可以通过undo读取之前的行版本信息,以此实现非锁定读取。
最后也是最为重要的一点是,undo log会产生redo log,也就是undo log的产生会伴随着redo log的产生,这是因为undo log也需要持久性的保护。
# 存储方式
- InnoDB存储引擎对undo的管理同样采用段的方式。但是这个段和之前介绍的段有所不同。首先InnoDB存储引擎有rollback segment,每个回滚段种记录了1024个undo log segment,而在每个undo log segment段中进行undo页的申请。共享表空间偏移量为5的页(0,5)记录了所有rollback segment header所在的页,这个页的类型为FIL_PAGE_TYPE_SYS。
- 事务在undo log segment分配页并写入undo log的这个过程同样需要写入重做日志。当事务提交时,InnoDB存储引擎会做以下两件事情:
- 将undo log放入列表中,以供之后的purge操作
- 判断undo log所在的页是否可以重用,若可以分配给下个事务使用
事务提交后并不能马上删除undo log及undo log所在的页。这是因为可能还有其他事务需要通过undo log来得到行记录之前的版本。故事务提交时将undo log放入一个链表中,是否可以最终删除undo log及undo log所在页由purge线程来判断。
# 重用undo页
在InnoDB存储引擎的设计中对undo页可以进行重用。具体来说,当事务提交时,首先将undo log放入链表中,然后判断undo页的使用空间是否小于3/4,若是则表示该undo页可以被重用,之后新的undo log记录在当前undo log的后面。由于存放undo log的列表是以记录进行组织的,而undo页可能存放着不同事务的undo log,因此purge操作需要涉及磁盘的离散读取操作,是一个比较缓慢的过程。
# undo log格式
在InnoDB存储引擎中,undo log分为:
- insert undo log insert undo log是指在insert操作中产生的undo log。因为insert操作的记录,只对事务本身可见,对其他事务不可见(这是事务隔离性的要求),故该undo log可以在事务提交后直接删除。不需要进行purge操作。
- update undo log update undo log记录的是对delete和update操作产生的undo log。该undo log可能需要提供MVCC机制,因此不能在事务提交时就进行删除。提交时放入undo log链表,等待purge线程进行最后的删除。
# undo操作
- insert操作完,在事务提交后,undo页会放入cache列表以供下次重用
- delete操作并不直接删除记录,而只是将记录标记为已删除,也就是将记录的delete flag设置为1。而记录最终的删除是在purge操作中完成的。
- update操作
- update非主键,两种情况
- 更新记录时,对于被更新的_每个列_来说,如果更新后的列和更新前的列占用的存储空间都一样大,那么就可以进行 就地更新 ,也就是直接在原记录的基础上修改对应列的值
- 如果有**任何一个**被更新的列更新前和更新后占用的存储空间大小不一致,那么就需 要先把这条旧的记录从聚簇索引页面中删除掉,然后再根据更新后列的值创建一条新的记录插入到页面中。这里所说的 删除 并不是 delete mark 操作,而是真正的删除掉,也就是把这条记录从 正 常记录链表 中移除并加入到 垃圾链表 中
- update主键的操作其实分两步完成
- 将旧记录进行 delete mark 操作,事务提交后才由专门的线程做purge操作,把它加入到垃圾链表中
- 根据更新后各列的值创建一条新记录,并将其插入到聚簇索引中(需重新定位插入的位置)
- update非主键,两种情况
# 事务id
一个事务可以是一个只读事务,或者是一个读写事务:
- 我们可以通过 START TRANSACTION READ ONLY 语句开启一个只读事务。
在只读事务中不可以对普通的表(其他事务也能访问到的表)进行增、删、改操作,但可以对临时表做增、 删、改操作。
- 我们可以通过 START TRANSACTION READ WRITE 语句开启一个读写事务,或者使用 BEGIN 、 START TRANSACTION 语句开启的事务默认也算是读写事务。
在读写事务中可以对表执行增删改查操作。
# 事务分配id的时机
如果某个事务执行过程中对某个表执行了增、删、改操作,那么 InnoDB 存储引擎就会给它分配一个独一无二的事务id
- 对于只读事务来说,只有在它第一次对某个用户创建的临时表执行增、删、改操作时才会为这个事务分配一个 事务id ,否则的话是不分配 事务id 的。
小贴士:
我们前边说过对某个查询语句执行EXPLAIN分析它的查询计划时,有时候在Extra列会看到Using temporary的提示,这个表明在执行该查询语句时会用到内部临时表。这个所谓的内部临时表和我们手动用CREATE TEMPORARY TABLE创建的用户临时表并不一样,在事务回滚时并不需要把执行SELECT语句过程中用到的内部临时表也回滚,在执行SELECT语句用到内部临时表时并不会为它分配事务 id。
- 对于读写事务来说,只有在它第一次对某个表(包括用户创建的临时表)执行增、删、改操作时才会为这个 事务分配一个 事务id ,否则的话也是不分配 事务id 的。 有的时候虽然我们开启了一个读写事务,但是在这个事务中全是查询语句,并没有执行增、删、改的语句, 那也就意味着这个事务并不会被分配一个 事务id 。
# 事务id是怎么生成的
这个 事务id 本质上就是一个数字,它的分配策略和我们前边提到的对隐藏列 row_id (当用户没有为表创建主键 和 UNIQUE 键时 InnoDB 自动创建的列)的分配策略大抵相同,具体策略如下:
- 服务器会在内存中维护一个全局变量,每当需要为某个事务分配一个 事务id 时,就会把该变量的值当作 事 务id 分配给该事务,并且把该变量自增1。
- 每当这个变量的值为 256 的倍数时,就会将该变量的值刷新到系统表空间的页号为 5 的页面中一个称之为 Max Trx ID 的属性处,这个属性占用 8 个字节的存储空间。
- 当系统下一次重新启动时,会将上边提到的 Max Trx ID 属性加载到内存中,将该值加上256之后赋值给我们前边提到的全局变量(因为在上次关机时该全局变量的值可能大于 Max Trx ID 属性值)。
这样就可以保证整个系统中分配的 事务id 值是一个递增的数字。先被分配 id 的事务得到的是较小的 事务id ,后被分配 id 的事务得到的是较大的 事务id 。
# trx_id隐藏列
聚簇索引的记录除了会保存完整的用户数据以外,而且还 会自动添加名为trx_id、roll_pointer的隐藏列,如果用户没有在表中定义主键以及UNIQUE键,还会自动添加一个 名为row_id的隐藏列。
 trx_id 就是某个对这个聚簇索引记录做改动的语句所在的事务对应的 事务id 而已 (此处的改动可以是 INSERT 、 DELETE 、 UPDATE 操作)。
trx_id 就是某个对这个聚簇索引记录做改动的语句所在的事务对应的 事务id 而已 (此处的改动可以是 INSERT 、 DELETE 、 UPDATE 操作)。
# roll_pointer 隐藏列
 roll_pointer 本质就是一个指针,指向记录对应的undo日志
roll_pointer 本质就是一个指针,指向记录对应的undo日志
# MVCC
准备工作
mysql> CREATE TABLE hero (
-> number INT,
-> name VARCHAR(100),
-> country varchar(100),
-> PRIMARY KEY (number)
-> ) Engine=InnoDB CHARSET=utf8;
Query OK, 0 rows affected (2.42 sec)
mysql> INSERT INTO hero VALUES(1, '刘备', '蜀');
Query OK, 1 row affected (0.31 sec)
mysql> SELECT * FROM hero;
+--------+--------+---------+
| number | name | country |
+--------+--------+---------+
| 1 | 刘备 | 蜀 |
+--------+--------+---------+
1 row in set (0.01 sec)
# 事务隔离级别
# 事务并发执行遇到的问题
- 脏写( Dirty Write ) 一个事务修改了另一个未提交事务修改过的数据

- 脏读( Dirty Read )
一个事务读到了另一个未提交事务修改过的数据

- 不可重复读(Non-Repeatable Read)
一个事务只能读到另一个已经提交的事务修改过的数据,并且其他事务每对该数据进行一次修改并提交 后,该事务都能查询得到最新值(两次select读取的数据不一样)

- 幻读(Phantom)
一个事务先根据某些条件查询出一些记录,之后另一个事务又向表中插入了符合这些条件的记录,原先的事务再次按照该条件查询时,能把另一个事务插入的记录也读出来

幻读 https://dev.mysql.com/doc/refman/5.7/en/glossary.html (opens new window) https://dev.mysql.com/doc/refman/5.7/en/innodb-next-key-locking.html (opens new window) https://stackoverflow.com/questions/42794425/unable-to-produce-a-phantom-read/42796969#42796969 (opens new window) https://en.wikipedia.org/wiki/Isolation_%28database_systems%29#Phantom_reads (opens new window)
# SQL标准中的四种隔离级别
- READ UNCOMMITTED :未提交读。
- READ COMMITTED :已提交读。
- REPEATABLE READ :可重复读。
- SERIALIZABLE :可串行化。
隔离级别与读取现象 '+' - 可能 '-' - 不可能
| 隔离级别 | 脏读 | 不可重复读 | 幻影 |
|---|---|---|---|
| READ UNCOMMITTED | + | + | + |
| READ COMMITTED | - | + | + |
| REPEATABLE READ | - | - | + |
| SERIALIZABLE | - | - | - |
也就是说:
- READ UNCOMMITTED 隔离级别下,可能发生 脏读 、 不可重复读 和 幻读 问题。
- READ COMMITTED 隔离级别下,可能发生 不可重复读 和_ 幻读_ 问题,但是不可以发生_ 脏读_ 问题。
- REPEATABLE READ 隔离级别下,可能发生_ 幻读 问题,但是不可以发生 脏读_ 和 不可重复读 的问题。
- SERIALIZABLE 隔离级别下,各种问题都不可以发生。
脏写 是怎么回事儿?怎么里边都没写呢?这是因为脏写这个问题太严重了,不论是哪种隔离级别,都不允许脏写的情况发生。
# MySQL中支持的四种隔离级别
不同的数据库厂商对 SQL标准 中规定的四种隔离级别支持不一样,比方说 Oracle 就只支持 READ COMMITTED 和 SERIALIZABLE 隔离级别。本书中所讨论的 MySQL 虽然支持4种隔离级别,但与 SQL标准 中所规定的各级隔离级 别允许发生的问题却有些出入,MySQL在REPEATABLE READ(默认)隔离级别下,是可以禁止幻读问题的发生的
设置事务隔离级别 SET [GLOBAL|SESSION] TRANSACTION ISOLATION LEVEL level;
- GLOBAL
全局设置
- SESSION
当前连接的设置
- 不写关键字 当前会话的下一个事务设置,执行完后回到之前的隔离级别
查看会话隔离级别
mysql> show variables like 'transaction_isolation';
+-----------------------+-----------------+
| Variable_name | Value |
+-----------------------+-----------------+
| transaction_isolation | REPEATABLE-READ |
+-----------------------+-----------------+
1 row in set, 1 warning (0.00 sec)
mysql> select @@transaction_isolation;
+-------------------------+
| @@transaction_isolation |
+-------------------------+
| REPEATABLE-READ |
+-------------------------+
1 row in set (0.00 sec)
# MVCC原理
# 版本链
对于使用 InnoDB 存储引擎的表来说,它的聚簇索引记录中都包含两个必要的隐藏列( row_id 并 不是必要的,我们创建的表中有主键或者非NULL的UNIQUE键时都不会包含 row_id 列):
- trx_id :每次一个事务对某条聚簇索引记录进行改动时,都会把该事务的 事务id 赋值给 trx_id 隐藏列。
- roll_pointer :每次对某条聚簇索引记录进行改动时,都会把旧的版本写入到 undo日志 中,然后这个隐藏列就相当于一个指针,可以通过它来找到该记录修改前的信息。
 每次对记录进行改动,都会记录一条 undo日志 ,每条 undo日志 也都有一个 roll_pointer 属性( INSERT 操作 对应的 undo日志 没有该属性,因为该记录并没有更早的版本),可以将这些 undo日志 都连起来,串成一个链表
每次对记录进行改动,都会记录一条 undo日志 ,每条 undo日志 也都有一个 roll_pointer 属性( INSERT 操作 对应的 undo日志 没有该属性,因为该记录并没有更早的版本),可以将这些 undo日志 都连起来,串成一个链表
 对该记录每次更新后,都会将旧值放到一条 undo日志 中,就算是该记录的一个旧版本,随着更新次数的增多, 所有的版本都会被 roll_pointer 属性连接成一个链表,我们把这个链表称之为 版本链 ,版本链的头节点就是当前记录最新的值。另外,每个版本中还包含生成该版本时对应的 事务id ,这个信息很重要,我们稍后就会用到。
对该记录每次更新后,都会将旧值放到一条 undo日志 中,就算是该记录的一个旧版本,随着更新次数的增多, 所有的版本都会被 roll_pointer 属性连接成一个链表,我们把这个链表称之为 版本链 ,版本链的头节点就是当前记录最新的值。另外,每个版本中还包含生成该版本时对应的 事务id ,这个信息很重要,我们稍后就会用到。
# ReadView
- 对于使用 READ UNCOMMITTED 隔离级别的事务来说,由于可以读到未提交事务修改过的记录,所以直接读取记录 的最新版本就好了;
- 对于使用 SERIALIZABLE 隔离级别的事务来说,设计 InnoDB 的大叔规定使用加锁的方式来访 问记录;
- 对于使用 READ COMMITTED 和 REPEATABLE READ 隔离级别的事务来 说,都必须保证读到已经提交了的事务修改过的记录,也就是说假如另一个事务已经修改了记录但是尚未提交, 是不能直接读取最新版本的记录的,核心问题就是:需要判断版本链中的哪个版本是当前事务可见的。为此,设计 InnoDB 的大叔提出了一个 ReadView 的概念,这个 ReadView 中主要包含4个比较重要的内容:
- m_ids :表示在生成 ReadView 时当前系统中活跃的读写事务的 事务id 列表。
- min_trx_id :表示在生成 ReadView 时当前系统中活跃的读写事务中最小的 事务id ,也就是 m_ids 中的最小值。
- max_trx_id :表示生成 ReadView 时系统中应该分配给下一个事务的 id 值。
小贴士:
注意max_trx_id并不是m_ids中的最大值,事务id是递增分配的。比方说现在有id为1,2,3这三个事务,之后id为3的事务提交了。那么一个新的读事务在生成ReadView时,m_ids就包括1和2,min_trx_id的值就是1,max_trx_id的值就是4。
- creator_trx_id :表示生成该 ReadView 的事务的 事务id 。
小贴士:
我们前边说过,只有在对表中的记录做改动时(执行INSERT、DELETE、UPDATE这些语句时)才会为事务分配事务id,否则在一个只读事务中的事务id值都默认为0。
有了这个 ReadView ,这样在访问某条记录时,只需要按照下边的步骤判断记录的某个版本是否可见:
- 如果被访问版本的 trx_id 属性值与 ReadView 中的 creator_trx_id 值相同,意味着当前事务在访问它自己修改过的记录,所以该版本可以被当前事务访问。
- 如果被访问版本的 trx_id 属性值小于 ReadView 中的 min_trx_id 值,表明生成该版本的事务在当前事务生 成 ReadView 前已经提交,所以该版本可以被当前事务访问。
- 如果被访问版本的 trx_id 属性值大于 ReadView 中的 max_trx_id 值,表明生成该版本的事务在当前事务生 成 ReadView 后才开启,所以该版本不可以被当前事务访问。
- 如果被访问版本的 trx_id 属性值在 ReadView 的 min_trx_id 和 max_trx_id 之间,那就需要判断一下trx_id 属性值是不是在 m_ids 列表中,如果在,说明创建 ReadView 时生成该版本的事务还是活跃的,该版本不可以被访问;如果不在,说明创建 ReadView 时生成该版本的事务已经被提交,该版本可以被访问。
如果某个版本的数据对当前事务不可见的话,那就顺着版本链找到下一个版本的数据,继续按照上边的步骤判断可见性,依此类推,直到版本链中的最后一个版本。如果最后一个版本也不可见的话,那么就意味着该条记录对该事务完全不可见,查询结果就不包含该记录。
在 MySQL 中, READ COMMITTED 和 REPEATABLE READ 隔离级别的的一个非常大的区别就是它们生成ReadView的时机不同
- READ COMMITTED
使用READ COMMITTED隔离级别的事务在每次查询开始时都会生成一个独立的ReadView
- REPEATABLE READ
对于使用 REPEATABLE READ 隔离级别的事务来说,只会在第一次执行查询语句时生成一个 ReadView ,之后的查询就不会重复生成了 生成ReadView的时机不同,READ COMMITTD在每一次进行普通SELECT操作前都会生成一个ReadView,而REPEATABLE READ只在第一次进行普通SELECT操作前生成一个ReadView,之后的查询操作都重复使用这个ReadView就好了
我们之前说执行DELETE语句或者更新主键的UPDATE语句并不会立即把对应的记录完全从页面中删除,而是执行一个所谓的delete mark操作,相当于只是对记录打上了一个删除标志位,这主要就是为MVCC服务的
# purge
delete和update操作可能并不直接删除原有的数据。例如,DELETE FROM t WHERE a=1;
表t上列a有聚集索引,列b上有辅助索引。对于上述的delete操作,仅是将主键列等于1的记录delete flag设 置为1,记录并没有被删除,即记录还是存在于B+树中。其次,对辅助索引上a等于1,b等于1的记录同样没有做任何处理。而真正删除这行记录的操作其实被“延时”了,最终在purge操作中完成。
purge用于最终完成delete和update操作。这样设计是因为InnoDB存储引擎支持MVCC,所以记录不能在事 务提交时立即进行处理。这时其他事物可能正在引用这行,故InnoDB存储引擎需要保存记录之前的版本。 而是否可以删除该条记录通过purge来进行判断。若该行记录已不被任何其他事务引用,那么就可以进行真 正的delete操作。可见,purge操作是清理之前的delete和update操作,将上述操作“最终”完成。而实际执行的操作为delete操作,清理之前行记录的版本。
# 锁
https://dev.mysql.com/doc/refman/5.7/en/innodb-locking.html (opens new window) https://dev.mysql.com/doc/refman/5.7/en/innodb-locks-set.html (opens new window)
# 一致性读(Consistent Reads)
事务利用 MVCC 进行的读取操作称之为 一致性读 ,或者 一致性无锁读 ,有的地方也称之为_ 快照读_ 。
所有普通 的 SELECT 语句( plain SELECT )在 READ COMMITTED 、_ REPEATABLE READ_ 隔离级别下都算是 一致性读 ,比方说:
SELECT * FROM t; SELECT * FROM t1 INNER JOIN t2 ON t1.col1 = t2.col2
一致性读 并不会对表中的任何记录做 加锁 操作,其他事务可以自由的对表中的记录做改动。
# 锁定读(Locking Reads)
共享锁和独占锁
- 共享锁 ,英文名: Shared Locks ,简称 S锁 。在事务要读取一条记录时,需要先获取该记录的 S锁 。
- 独占锁 ,也常称 排他锁 ,英文名: Exclusive Locks ,简称 X锁 。在事务要改动一条记录时,需要先获取该记录的 X锁 。
S锁和S锁兼容,同一时刻可以有多个S锁;S锁和X锁不兼容,同一时刻只能持有一个锁(X或S)
- SS兼容
- SX互斥
- XX互斥
锁定读的语句
- 对读取的记录加 S锁 :
SELECT ... LOCK IN SHARE MODE;
假如当前事务执行此语句,对读取到的记录加 S锁,其他事务还可以继续读取加 S锁,但是不能对这些记录加 X锁,除非等 S锁 释放
- 对读取的记录加 X锁 :
SELECT ... FOR UPDATE;
如果当前事务执行了该语句,那么它会为读取到的记录加 X锁 ,这样既不允许别的事务获取这些记录的 S锁 和 X 锁,必须要等这个事务结束后将记录上的 X锁 释放
# 写操作
- DELETE :
对一条记录做 DELETE 操作的过程其实是先在 B+ 树中定位到这条记录的位置,然后获取一下这条记录的 X锁 ,然后再执行 delete mark 操作。我们也可以把这个定位待删除记录在 B+ 树中位置的过程看成是一个获取 X锁 的锁定读 。
- UPDATE :
在对一条记录做 UPDATE 操作时分为三种情况:
- 如果未修改该记录的键值并且被更新的列占用的存储空间在修改前后未发生变化,则先在 B+ 树中定位到这条记录的位置,然后再获取一下记录的 X锁 ,最后在原记录的位置进行修改操作。其实我们也可以 把这个定位待修改记录在 B+ 树中位置的过程看成是一个获取 X锁 的 锁定读 。
- 如果未修改该记录的键值并且至少有一个被更新的列占用的存储空间在修改前后发生变化,则先在B+ 树中定位到这条记录的位置,然后获取一下记录的 X锁 ,将该记录彻底删除掉(就是把记录彻底移入垃圾链表),最后再插入一条新记录。这个定位待修改记录在 B+ 树中位置的过程看成是一个获取 X 锁 的 锁定读 ,新插入的记录由 INSERT 操作提供的 隐式锁 进行保护。
- 如果修改了该记录的键值,则相当于在原记录上做 DELETE 操作之后再来一次 INSERT 操作,加锁操作就 需要按照 DELETE 和 INSERT 的规则进行了。
- INSERT :
一般情况下,新插入一条记录的操作并不加锁,设计 InnoDB 的大叔通过一种称之为 隐式锁 的东东来保护这条新插入的记录在本事务提交前不被别的事务访问
# 多粒度锁
我们前边提到的 锁 都是针对记录的,也可以被称之为 行级锁 或者 行锁 ,对一条记录加锁影响的也只是这条记录而已,我们就说这个锁的粒度比较细;其实一个事务也可以在 表 级别进行加锁,自然就被称之为 _表级锁 _或 者 表锁 ,对一个表加锁影响整个表中的记录,我们就说这个锁的粒度比较粗。给表加的锁也可以分为 共享锁 ( S锁 )和 独占锁 ( X锁 ):
- 给表加 S锁 :
如果一个事务给表加了 S锁 ,那么:
- 别的事务可以继续获得该表的S锁
- 别的事务可以继续获得该表中的某些记录的S锁
- 别的事务不可以继续获得该表的X锁
- 别的事务不可以继续获得该表中的某些记录的X锁
- 给表加 X锁 :
如果一个事务给表加了 X锁 (意味着该事务要独占这个表),那么:
- 别的事务不可以继续获得该表的S锁
- 别的事务不可以继续获得该表中的某些记录的S锁
- 别的事务不可以继续获得该表的X锁
- 别的事务不可以继续获得该表中的某些记录的X锁
意向锁(Intention Locks )
- 意向共享锁,英文名: Intention Shared Lock ,简称 IS锁 。当事务准备在某条记录上加 S锁 时,需要先在表级别加一个 IS锁 。
- 意向独占锁,英文名: Intention Exclusive Lock ,简称 IX锁 。当事务准备在某条记录上加 X锁 时,需 要先在表级别加一个 IX锁 。
IS、IX锁是表级锁,它们的提出仅仅为了在之后加表级别的S锁和X锁时可以快速判断表中的记录是否 被上锁,以避免用遍历的方式来查看表中有没有上锁的记录,也就是说其实**IS锁和IX锁是兼容的,IX锁和IX锁是 兼容的。**兼容是指对同一记录锁的兼容性情况
| 兼容性 | X | IX | S | IS |
|---|---|---|---|---|
| X | 不兼容 | 不兼容 | 不兼容 | 不兼容 |
| IX | 不兼容 | 兼容 | 不兼容 | 兼容 |
| S | 不兼容 | 不兼容 | 兼容 | 兼容 |
| IS | 不兼容 | 兼容 | 兼容 | 兼容 |
上边说的都算是些理论知识,其实 MySQL 支持多种存储引擎,不同存储引擎对锁的支持也是不一样的。
对于 MyISAM 、 MEMORY 、 MERGE 这些存储引擎来说,它们只支持表级锁,而且这些引擎并不支持事务,所以使 用这些存储引擎的锁一般都是针对当前会话来说的。InnoDB 存储引擎既支持表锁,也支持行锁。
# InnoDB中的表级锁
- 表级别的 S锁 、 X锁
在对某个表执行 SELECT 、 INSERT 、 DELETE 、 UPDATE 语句时, InnoDB 存储引擎是不会为这个表添加表级别的 S锁 或者 X锁 的。 一般情况下也不会使用 InnoDB 存储引擎自己提供的表级别的 S锁 和 X锁 。 只会在一些特殊情况下,比方说崩溃恢复过程中用到
LOCK TABLES t READ: InnoDB 存储引擎会对表 t 加表级别的 S锁 。LOCK TABLES t WRITE: InnoDB 存储引擎会对表 t 加表级别的 X锁 。
另外,在对某个表执行一些诸如 ALTER TABLE 、 DROP TABLE 这类的 DDL 语句。这个过程其实是通过在 server层 使用一种称之为 元数据锁 (英文名: Metadata Locks ,简称 MDL )来实现的 (DDL语句执行时会隐式的提交当前会话中的事务)
- 表级别的 IS锁 、 IX锁
当我们在对使用 InnoDB 存储引擎的表的某些记录加 S锁 之前,那就需要先在表级别加一个 IS锁 ,当我们 在对使用 InnoDB 存储引擎的表的某些记录加 X锁 之前,那就需要先在表级别加一个 IX锁 。 IS锁 和 IX锁 的使命只是为了后续在加表级别的 S锁 和 X锁 时判断表中是否有已经被加锁的记录,以避免用遍历的方式来 查看表中有没有上锁的记录。
- 表级别的 AUTO-INC锁
在使用 MySQL 过程中,我们可以为表的某个列添加
AUTO_INCREMENT属性,之后在插入记录时,可以不指定该列的值,系统会自动为它赋上递增的值系统实现这种自动给 AUTO_INCREMENT 修饰的列递增赋值的原理主要是两个:- 采用 AUTO-INC 锁,也就是在执行插入语句时就在表级别加一个 AUTO-INC 锁,然后为每条待插入记录的 AUTO_INCREMENT 修饰的列分配递增的值,在该语句执行结束后,再把 AUTO-INC 锁释放掉。这样一个事务在持有 AUTO-INC 锁的过程中,其他事务的插入语句都要被阻塞,可以保证一个语句中分配的递增 值是连续的。 这个AUTO-INC锁的作用范围只是单个插入语句,插入语句执行完成后,这个锁就被释放了
- 采用一个轻量级的锁,在为插入语句生成 AUTO_INCREMENT 修饰的列的值时获取一下这个轻量级锁,然后生成本次插入语句需要用到的 AUTO_INCREMENT 列的值之后,就把该轻量级锁释放掉,并不需要等到整个插入语句执行完才释放锁。
设计InnoDB的大叔提供了一个称之为innodb_autoinc_lock_mode的系统变量来控制到底使用上述两种方式中的哪种来为AUTO_INCREMENT修饰的列进行赋值
- 当innodb_autoinc_lock_mode值 为0时,一律采用AUTO-INC锁;
- 当innodb_autoinc_lock_mode值为2时,一律采用轻量级锁;
- 当 innodb_autoinc_lock_mode值为1时,两种方式混着来(也就是在插入记录数量确定时采用轻量级锁,不确定时使用AUTO-INC锁)。
不过当innodb_autoinc_lock_mode值为2时,可能会造成不同事务中的插入语句为AUTO_INCREMENT修饰的列生成的值是交叉的,在有主从复制的场景中是不安全的。
# InnoDB中的行级锁
行锁 ,也称为 记录锁 ,顾名思义就是在记录上加的锁。
准备工作
mysql> CREATE TABLE hero (
-> number INT,
-> name VARCHAR(100),
-> country varchar(100),
-> PRIMARY KEY (number),
-> KEY idx_name (name)
-> ) Engine=InnoDB CHARSET=utf8;
Query OK, 0 rows affected (0.41 sec)
mysql> INSERT INTO hero VALUES
-> (1, 'l刘备', '蜀'),
-> (3, 'z诸葛亮', '蜀'),
-> (8, 'c曹操', '魏'),
-> (15, 'x荀彧', '魏'),
-> (20, 's孙权', '吴');
Query OK, 5 rows affected (0.10 sec)
Records: 5 Duplicates: 0 Warnings: 0
mysql> SELECT * FROM hero;
+--------+------------+---------+
| number | name | country |
+--------+------------+---------+
| 1 | l刘备 | 蜀 |
| 3 | z诸葛亮 | 蜀 |
| 8 | c曹操 | 魏 |
| 15 | x荀彧 | 魏 |
| 20 | s孙权 | 吴 |
+--------+------------+---------+
5 rows in set (0.02 sec)
 行锁类型
行锁类型
- Record Locks
官方的类型名称:LOCK_REC_NOT_GAP
记录锁是对索引记录的锁。有S锁和X锁之分。
记录锁总是锁定索引记录,即使定义的表没有索引。对于这种情况, InnoDB创建一个隐藏的聚集索引(raw)并将该索引用于记录锁定。
比方说我们把 number 值为 8 的那条记录加一个 Record Lock

- Gap Locks
间隙锁是在索引记录之间(不包含记录本身)的间隙上的锁,或在第一条索引记录之前或最后一条索引记录之后的间隙上的锁。
比方说我们把 number 值为 8 的那条记录加一个 Gap Lock
 为 number 值为 8 的记录加了 gap锁 ,意味着不允许别的事务在 number 值为 8 的记录前边的 间隙 插入新记录,其实就是 number 列的值 (3, 8) 这个区间的新记录是不允许立即插入的。比方说有另外一个事务再想插入一条 number 值为 4 的新记录,它定位到该条新记录的下一条记录的 number 值为8,而这条记录上又有一个 gap锁 ,所以就会阻塞插入操作,直到拥有这个 gap锁 的事务提交了之后, number 列的值在区 间 (3, 8) 中的新记录才可以被插入。
为 number 值为 8 的记录加了 gap锁 ,意味着不允许别的事务在 number 值为 8 的记录前边的 间隙 插入新记录,其实就是 number 列的值 (3, 8) 这个区间的新记录是不允许立即插入的。比方说有另外一个事务再想插入一条 number 值为 4 的新记录,它定位到该条新记录的下一条记录的 number 值为8,而这条记录上又有一个 gap锁 ,所以就会阻塞插入操作,直到拥有这个 gap锁 的事务提交了之后, number 列的值在区 间 (3, 8) 中的新记录才可以被插入。
这个 gap锁 的提出仅仅是为了防止插入幻影记录而提出的,虽然有 共享gap锁 和 独占gap锁 这样的说法, 但是它们起到的作用都是相同的。而且如果你对一条记录加了 gap锁 (不论是 共享gap锁 还是 独占gap锁 ),并不会限制其他事务对这条记录加 Record Lock 或者继续加 Gap Lock。允许冲突间隙锁的原因是,如果从索引中清除记录,则必须合并不同事务在记录上持有的间隙锁。
最大和最小记录的间隙如何锁,使用数据页的两个伪记录
- Infimum 记录,表示该页面中最小的记录。
- Supremum 记录,表示该页面中最大的记录。
阻止其他事务插入 number 值在 (20, +∞) 这个区间的新记录,我们可以给索引中的最后一条记录,也就是 number 值为 20 的那条记录所在页面的 Supremum 记录加上一个 gap锁

- Next-Key Locks 官方的类型名称: LOCK_ORDINARY next-key锁 的本质就是一个 Record Lock 和一个 Gap Lock 的合体,它既能保护该条记录,又能阻止别的事务 将新记录插入被保护记录前边的 间隙

- Insert Intention Locks
我们说一个事务在插入一条记录时需要判断一下插入位置是不是被别的事务加了所谓的 gap锁 ( next-key锁 也包含 gap锁),如果有的话,插入操作需要等待,直到拥有 gap锁 的那个事务提 交。但是设计 InnoDB 的大叔规定事务在等待的时候也需要在内存中生成一个 锁结构 ,表明有事务想在某个 间隙 中插入新记录,但是现在在等待。设计 InnoDB 的大叔就把这种类型的锁命名为 Insert Intention Locks ,官方的类型名称为: LOCK_INSERT_INTENTION ,我们也可以称为 插入意向锁 。
比方说我们把 number 值为 8 的那条记录加一个 插入意向锁 的示意图如下
 比方说现在 T1 为 number 值为 8 的记录加了一个 gap锁 ,然后 T2 和 T3 分别想向 hero 表中插入 number 值分别为 4 、 5 的两条记录,所以现在为 number 值为 8 的记录加的锁的示意图就如下所示
比方说现在 T1 为 number 值为 8 的记录加了一个 gap锁 ,然后 T2 和 T3 分别想向 hero 表中插入 number 值分别为 4 、 5 的两条记录,所以现在为 number 值为 8 的记录加的锁的示意图就如下所示
 从图中可以看到,由于 T1 持有 gap锁 ,所以 T2 和 T3 需要生成一个 插入意向锁 的 锁结构 并且处于等待状态。当 T1 提交后会把它获取到的锁都释放掉,这样 T2 和 T3 就能获取到对应的 插入意向锁 了(本质上就是把插入意向锁对应锁结构的 is_waiting 属性改为 false ), T2 和 T3 之间也并不会相互阻塞,它们可以同时获取到 number 值为8的 插入意向锁 ,然后执行插入操作。事实上插入意向锁并不会阻止别的事务继续获取该记录上任何类型的锁( 插入意向锁 就是这么鸡肋)
从图中可以看到,由于 T1 持有 gap锁 ,所以 T2 和 T3 需要生成一个 插入意向锁 的 锁结构 并且处于等待状态。当 T1 提交后会把它获取到的锁都释放掉,这样 T2 和 T3 就能获取到对应的 插入意向锁 了(本质上就是把插入意向锁对应锁结构的 is_waiting 属性改为 false ), T2 和 T3 之间也并不会相互阻塞,它们可以同时获取到 number 值为8的 插入意向锁 ,然后执行插入操作。事实上插入意向锁并不会阻止别的事务继续获取该记录上任何类型的锁( 插入意向锁 就是这么鸡肋)
其中对于唯一键值的锁定,Next-Key Lock 降级为 Record Lock 仅存在于查询所有的唯一索引列。若唯一索引由多个列组成,而查询仅是查找多个唯一索引列中的其中一个,那么查询其实是 range 类型查询,而不是 point 类型查询,故 InnoDB 存储引擎依然使用 Next-Key Lock 进行锁定
# 死锁
在InnoDB存储引擎中,参数 innodb_lock_wait_timeout 用 来设置超时的时间。默认50S;
因此,除了超时机制,当前数据库还都普遍采用wait-for graph(等待图)的方式来进行死锁检测。较之超时的解决方案,这是一种更为主动的死锁检测方式。InnoDB存储引擎也采用的这种方式。wait-for graph要求数据库保存 以下两种信息:
- 锁的信息链表
- 事务等待链表
 事务T1指向T2边的定义为:
事务T1指向T2边的定义为:
- 事务T1等待事务T2所占用的资源
- 事务T1最终等待T2所占用的资源,也就是事务之间在等待相同的资源,而事务T1发生在事务T2的后面
通过等待图可以发现存在回路(t1,t2),因此存在死锁。通过上述的介绍,可以发现wait-for graph是一种较为主动的死锁检测机制,在每个事务请求锁并发生等待时都会判断是否存在回路,若存在则有死锁,通常 来说InnoDB存储引擎选择回滚undo量最小的事务。